VMware virtual machine restore workflow
 Business Enterprise Elite
Business Enterprise Elite
Virtual machine restore
If you have taken a VMware backup, you can restore:
| Restore Type | Description |
|---|---|
| Full virtual machine | Restores the entire VM. |
| Data Restore | Restores VMDKs, files and folders Druva provides you with the capability to restore files to CIFS/SMB share and any virtual machine in your vCenter/ESXi. Druva also supports file-level restore to the guest virtual machine in the VMC environment. Druva supports file-level restore to a CIFS/SMB share in the VMC environment. This CIFS/SMB share also could belong to a virtual machine and needs to be accessible from the backup proxy. |
| Instant Restore | Instantly restores the virtual machines that are mapped to Druva CloudCache (Linux version). For more information, see Restore virtual machines instantly. |
MS-SQL Restore (from application-aware backups)
At the time of configuring virtual machines for backup, you were asked if you wanted to enable application-aware processing. Druva supports SQL Server aware backups, it provides the following options to restore databases:
| Restore Type | Description |
|---|---|
| Database restore: Restore SQL Server databases using recovery points. | When you enable application-aware backup on VMware virtual machines, Druva detects the applications inside the virtual machine and takes a backup of the data that the application generates. Since Druva supports backup of Microsoft SQL Server databases inside VMs, it takes VSS recovery points of the SQL Server instances and uploads it to the Druva Cloud along with the virtual machine recovery point. Now, when you want to restore the database to a virtual machine, you can choose a recovery point and Druva restores the databases to a state that was backed up in the selected recovery point. |
| Point In Time restore: Restore SQL Server databases to a point in time using transaction logs | Transaction logs are a tool to restore databases to a point in time in between database recovery points. Druva can back up transaction logs in addition to the database recovery points so that you can get a tighter recovery time objective (RTO). When you enable SQL Server aware backup on VMware VMs, Druva provides an option to enable transaction log backups. If you enable it, Druva uses the virtual device interface (VDI) to back up and upload the transaction logs to Druva Cloud at specified intervals until the next full SQL Server aware virtual machine recovery point is backed up. Now, you can choose a point in time to restore databases. Druva restores the databases to the transaction with a timestamp that is closest to the point in time that you choose. |
| Transaction Mark restore: Restore SQL Server databases using transaction marks | If you enable transaction log backups for databases, Druva can utilize transaction marks to identify specific transactions. At the time of restoring databases, you can choose transactions that are marked to restore databases up to the point when these transactions occurred. |
Restore virtual machine workflow
The following diagram illustrates the restore workflow:
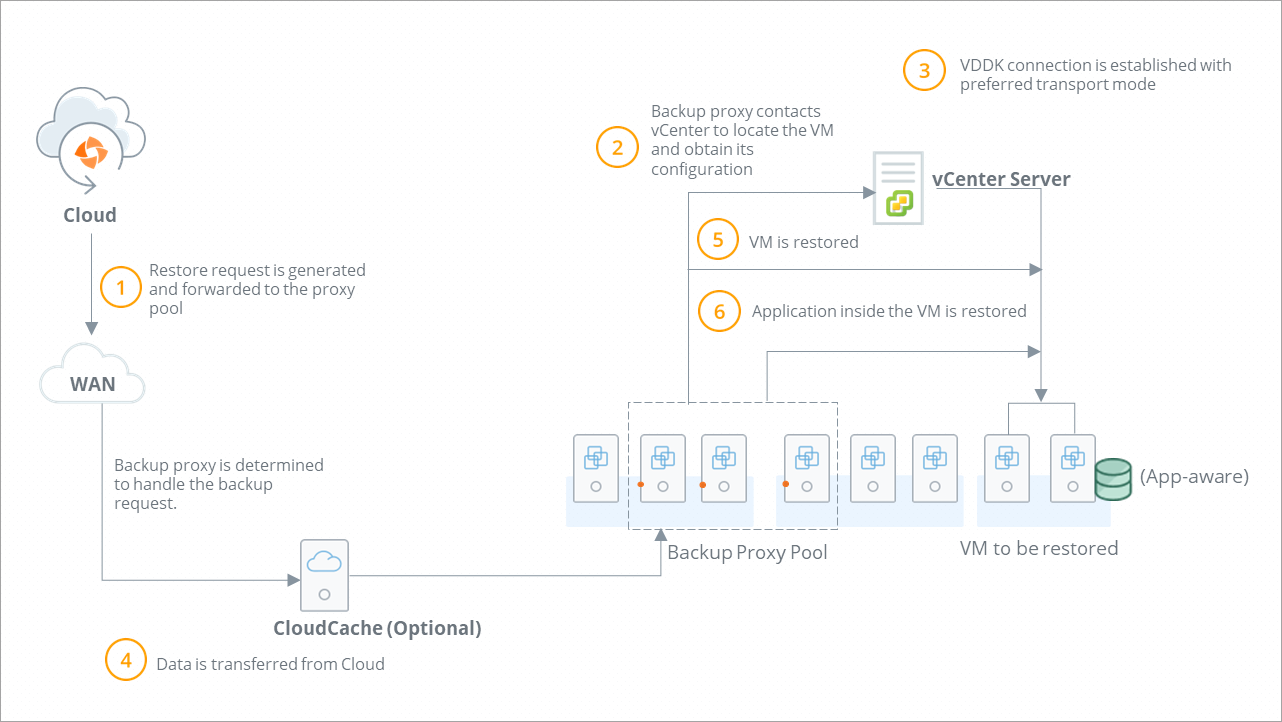
| Step | Operations |
|---|---|
| Step 1 |
Administrator initiates virtual machine restore. Druva forwards the restore request to the backup proxy pool.
|
| Step 2 |
|
| Step 3 |
VDDK connection is established with the virtual machine with SSL transport mode. Backup proxy checks if it is a full virtual machine restore or a VMDK file restore. Backup proxy contacts the virtual machine and establishes a write connection to restore virtual machine data.
|
| Step 4 | Backup proxy obtains the virtual machine data from Druva Cloud. |
| Step 5 |
Restore operations starts. Druva checks if the restore completes successfully.
|
| Step 6 | For Microsoft SQL database (with application-aware backup), the application is restored. |
Types of recovery point
Hot recovery point
Hot recovery points are point-in-time images of backup data stored on CloudCache. Hot recovery points are created only if you have CloudCache deployed and configured in your virtual infrastructure.
Typically, hot recovery points are maintained for:
- Data proximity - Keep a local copy of data on-premises
- Faster RTO - Enabling quicker restore time in event of a failure.
A restore of hot recovery points is an on-demand restore of virtual machine data that resides in CloudCache. Such a restore operation continues until your data is restored to the location that you specified.
Warm recovery point
Warm recovery points are point-in-time images of data dating back to 90 days in time that are stored in warm storage.
Typically, warm recovery points are maintained for:
- To reduce the on-premise footprint and save cost.
- Protect backup data against ransomware attacks.
Restores of warm recovery points are on-demand restores of virtual machine data dating back to 90 days in time. Restores of warm recovery points continue till the data is restored to the location that you specified.
Cold recovery point
The availability of this feature is limited based on the license type, region, and other criteria. To access this feature, contact your Druva Account Manager or Druva Support. This content is subject to change based on the continuous improvements to this feature.
Cold recovery points are point-in-time copies of backup data older than 15 days. These recovery points are stored in the Amazon Glacier Deep Archive.
Typically, cold recovery points are maintained for:
- Long term data which over a period is hardly accessed or restored.
- Need to store this data for compliance and audit purposes.
- Cheaper storage and cost savings.
At the time of restore, data from the cold tier is retrieved, moved temporarily to the warm tier, and then restored.
Once you click Restore and initiate the restoration process, the data retrieval from cold tier and its restore from the warm tier happen automatically. Warmed up data is deleted from the warm tier after 10 days.