SQL FAQs
This topic contains the following sections:
Overview FAQs
► How does the Druva deduplication algorithm work?- Druva uses a deduplication technique that makes use of a variable block sizing technique based on file type to determine globally duplicated data across all your servers. The Hybrid Workloads agent only transfers unique blocks of data to the cloud. This ensures massive bandwidth savings of up to 90% in many cases.
► Where is my data backed up?- Druva backs up your data in the cloud hosted by Amazon. Druva relies on the robustness and the security standards of Amazon Web Services to ensure that your backup data stays safe and secure.
► What does Druva back up?- Druva provides support for backup of MDF, NDF, and LDF files.
► What happens if my server loses connectivity?- Druva is designed to work efficiently even for organizations with intermittent connectivity. If Hybrid Workloads agents cannot reach Druva Cloud, backups or restores stop temporarily. When connectivity resumes, backups or restores start again. A single backup can, therefore, span across multiple backup windows.
► What are recovery points?- A recovery point is a point-in-time image of your backup data. To know the type of recovery points that Druva supports, see Common terms.
► My server is not operational. I want to replace it with another one. Can I?- Druva retains the data from your server that is not operational. You can restore the data to another server.
► I deprecate servers every 3 years. Can I configure new servers in their place?- Yes, you can. Druva retains data from the servers that you deprecate. To set up new servers in their place, restore the data from the deprecated servers to the new servers.
► What are restores of warm and cold recovery points?- The term "warm" and "cold" signify how old your data is. Restores using warm recovery points are performed for data that is no more than 90 days old. The data is stored in the warm storage. At the end of 90 days, the data is transferred to cold storage, where it resides for as long as you define in the retention policies. For such data, you must use cold recovery points to perform a restore. To know more about hot restore and cold restore, see Common terms.
- Defreeze is the process of preparing cold recovery points for restore. During a defreeze operation, Druva retrieves cold recovery points from cold storage and makes the data available for restore.
- Thawed data is a cold recovery point that has undergone a defreeze operation. The thawed data is available for restore for a specific duration.
► How does Druva handle data availability requirements for regulatory or legal purposes?- Druva stores backups for as long as you need. You can choose from multiple data retention options - as short as 90 days and up to the end of time for retaining data. Data older than 90 days is stored in cold storage. For data that is less than 90 days old, you can perform an on-demand restore.
► I want to back up secondary servers only if the primary server fails. Can I do this?- No, you cannot. However, you can create backup sets to back up the content from your secondary servers and your tertiary servers. Druva will back up data from your primary, secondary, and tertiary servers according to the schedule defined in the backup policy.
► Can I specify a bandwidth for backup?- Yes, you can specify the bandwidth limitation for backup.
► Can I specify a bandwidth for restore?- No, you cannot specify the bandwidth limitation for restore.
► What happens to my data after my contract expires?- After the expiration of your contract, Druva does not back up your servers. However, your data is retained on the cloud. You can choose to extend your contract, and then perform a restore of the data.
► Can I export Druva data?- No, you cannot export Druva data. However, you can choose to restore data to the server to which it belongs, or a new server.
► Can I perform a restore to a server in another organization under Druva?- Organizations in Druva are independent entities by design. Druva does not have a functionality that allows inter-Organizational restore.
Supportability FAQs
►Does Druva support both on-premise and cloud infrastructure to backup and recover SQL Servers?-
Yes, Druva supports backup and restore of SQL Servers running on the on-premise physical and virtual infrastructure, as well as cloud infrastructure such as Amazon EC2, Azure VMs, Google Compute Engines, and so on.
►How does Druva protect the SQL workloads on Microsoft Azure?-
Druva supports agent-based backup for databases that enables you to leverage SQL agent and deploy it in any of the supported Operating Systems on an Azure VM and protect these workloads. Configuration and backup/restore workflows remain the same whether data is located on-premise or on any Cloud like Azure. Another added advantage is that you can restore the data to any target residing either in the customer’s data center or private or public cloud.
Databases like SQL on Azure VM instances can be backed up using the agent-based backup method.
Configuration FAQs
►After the Hybrid Workloads agent is upgraded from older clients to version 4.7.1 or later, what happens to my existing backup sets?- After you upgrade the client,
- The MS-SQL backup sets configured to back up all instances in the content rule are auto-disabled.
- Hybrid Workloads agent discovers the existing instances on the server.
- Druva creates a new backup set for each instance present on the physical server. All the newly created backup sets have the same policy and same content rule as that of the earlier backup set for the All instances.
- Druva allows you to restore data from the All instances MS-SQL backup sets. If you have backup sets on the older clients, which were created for a particular instance, backups for those backup sets run without any change.
- If you do not upgrade from the older clients to 4.7.1 or later, backup jobs for the existing MS-SQL backup set will continue to run as configured. However, you will not be able to create new SQL backup set with Hybrid Workloads agent versions older than 4.7.1.
► How do I configure my SQL servers for backup?- To know how you can configure SQL servers for backup, see Introduction to Druva for SQL servers.
► What do I need to know before performing a configuration of my SQL servers?- Before configuring your SQL servers, we recommend that you read SQL server prerequisites and limitations. The checklist should help you perform a configuration that is best-suited for your environment.
► Unable to create MS-SQL backup sets for Hybrid Workloads agents older than version 4.7.1.- You cannot create MS-SQL backup sets for Hybrid Workloads agents older than version 4.7.1. However, backups for the old backup sets continue to run as configured.
► Can Druva discover the running MS-SQL instances and AGs on Hybrid Workloads agents older than version 4.7.1?- No. Druva cannot discover MS-SQL instances and AGs running on the server installed with an agent older than version 4.7.1.
► Why do I see additional backup sets created post-upgrade of the Hybrid Workloads agent to version 4.7.1?- Druva creates a new backup set for each instance present on the physical server. All the newly created backup sets have the same backup policy and same content rule as that of the earlier backup sets for All instances.
► My database files are stored on a Cluster Shared Volume, so the default Microsoft Shadow Copy Provider cannot take a recovery point of these files. How do I make the Hybrid Workloads agent use the Microsoft CSV Shadow Copy Provider?-
- From the command prompt, run the following command:
vssadmin list providers
Running this command displays a list of VSS providers, and the provider IDs. Copy the Microsoft CSV Shadow Copy Provider ID.
- Stop the Hybrid Workloads agent service.
- Open the Phoenix.cfg file in a text editor. The Phoenix.cfg file is available at the following location on Windows Server 2019, 2016, 2012 and 2008: C:\ProgramData\Phoenix
- Add the VSS_PROVIDER_ID parameter, and set its value to match the Microsoft CSV Shadow Copy Provider ID you obtained in the first step.
Use the following format to add the Microsoft CSV Shadow Copy Provider ID:
VSS_PROVIDER_ID = '<Provider ID>'
For example:VSS_PROVIDER_ID = '{b5946137-7b9f-4925-af80-51abd60b20d5}' - Save the Phoenix.cfg file.
- Start the Hybrid Workloads agent service.
- From the command prompt, run the following command:
Backup and restore FAQs
► What type of backups does Druva perform on SQL servers?-
The first backup of your servers is a full backup. Thereafter, Druva performs an incremental backup. Additionally, Druva also supports differential and transaction log backups of SQL servers. To know more, see Common terms.
► How do I back up or restore my data?- To know how to back up your SQL servers, see Back up servers . To know how to restore SQL servers, see SQL server restore.
► How does Druva back up or restore my SQL server data?- To understand the workflow at the time of backup, see full backup, differential backup, and log backup.
To know how Druva restores your file server data, see SQL server restore.
► What do I do if the SQL server transaction log backup fails with VSS1 error?- Check whether you have SQL standalone or SQL FCI installation done. In case you have SQL FCI, upgrade to build 4.7.1 or later and follow setup instructions as described in Configure Druva for the backup of databases in SQL Failover Cluster Instance (FCI).
► Why is the destination disk backup path for native SQL backups removed after taking the backup with Druva?-
If the first backup is taken on the disk and the next backup is taken on the Virtual device / URL, then SQL Server Management Studio (SSMS) replaces the path selected for disk backup with the latest backup path. This is the current behavior.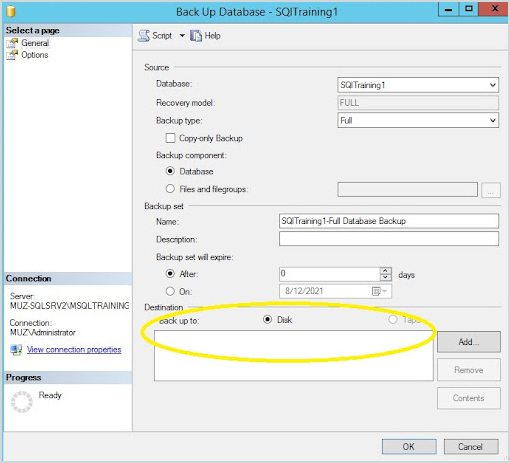
However, when a backup is taken on a virtual device, SSMS removes the disk backup path set in the native SQL backups after the backups are completed. This problem occurs only when the backup is configured via native utility and Druva.
It is important to understand the backup strategy and why the same database has to be backed up twice. This problem will never arise if the backup is only configured via Druva.