Backup and restore methods available for MS-SQL server databases
 Business Enterprise Elite
Business Enterprise Elite This article provides information on backup jobs such as:
Prerequisites
Before Druva can back up your databases, you have to configure your server for backup and restore. See, Quick steps to set up Druva to back up databases.
Full backups
Druva performs an ever incremental backup of the databases of your MS-SQL server. As mentioned in the prerequisites, backup and restore operations depend on VSS and SQL writer services. When a full backup is triggered based on the backup policy, Hybrid Workloads agent communicates with the SQL writer service using the VSS framework. The Hybrid Workloads agent executes a full scan of all the databases included in the backup. If your databases are getting backed up for the first time, the databases are backed up entirely. If your databases are not getting backed up for the first time, a full scan of the databases is executed but only the updates to your databases are backed up after deduplication is applied. When the backup job is successful, Druva creates a recovery point in your storage.
Understanding recovery points created using full backup
All recovery points created within the number of days specified under Retain Daily Recovery points for are retained. Suppose you have chosen to retain daily recovery points for 10 days. The full backup is scheduled to run on Wednesday, 12:00:00 PM PST every week. Between February 1, 2017, and February 28, 2017, Wednesday falls on 1st, 8th, 15th, and 22nd. The full backup is triggered on February 1, 2017, and a recovery point is created at 4:00:00 PM when the job is successful. On February 8, 2017, another full recovery point is created at 3:00:00 PM. Since the daily recovery points are retained for 10 days, before February 11, 2017, 11:59:59 PM, the full recovery points created on February 1, 2017, and February 8, 2017, are retained. After February 11, 2017, 11:59:59 PM, the February 1, 2017 recovery point is retained based on your weekly, monthly, and yearly retention periods.
Restoring a database from a recovery point created after a full backup
For example, you are restoring your database on February 12, 2017, at 11:00:00 AM. When you trigger a restore job from the Management Console, you see the following recovery point options to restore your data from:
- Hot
- Warm
- Cold
Druva retains a recovery point in warm storage for 90 days. If the recovery point created on February 1, 2017, is the latest recovery point in the week ending February 5, 2017, 11:59:59 PM, it is retained based on the weekly retention period. The recovery points created on February 1, 2017, and February 8, 2017, fall under warm recovery points. You can directly restore your database using a warm recovery point. A recovery point created in November, and retained based on the retention period can be considered as a cold recovery point for this example. You can see hot recovery points if you have configured CloudCache. To read more about CloudCache and hot recovery points, see CloudCache.
Workflow
The full backup contains the following steps:
- Druva checks if the agent is running. If the agent is not running, Druva queues the backup request. The request is executed after Hybrid Workloads agent is up and running.
- Before the backup operation starts, agent checks if VSS Service and SQL Writer service are running or not. If the services are not running, then the agent attempts to boot these processes automatically.
- During the estimate phase, the agent fetches the database information from MS-SQL server using the Volume Shadow Copy API.
- The agent then determines the distinct filesets, which should be backed up. VSS then provides a recovery point.
- If you are backing up your databases for the first time, entire recovery point is backed up. If you are not backing up your databases for the first time, updated data, in terms of filesets, is copied from the recovery point and uploaded to the server. The backup is marked as successful after data is successfully uploaded to the server.
Additional information
- The VSS recovery point is transient and is deleted automatically by the operating system. If the hard drive is not accessible, the VSS and MS-SQL server may take some time to recognize and update their internal file information.
- Backup may fail if it is triggered during this time interval while database files are moved to the partition containing deleted files.
- Backup jobs can be completed successfully after VSS and MS-SQL server update internal file information. But if some database files are moved to the deleted files partition and some other files are still available on the logical partition, the backup always fails. As a workaround, you have to clean this database manually.
- The system database tempdb is never backed up.
- During backup, database entities get backed-up in following order:
- Database files: MDF, LDF and NDF files
- Agent-specific metadata (json data)
- VSS backup document (XML data)
- SQL Writer metadata document (XML data)
- Sentinel (json data)
- On your server, if
- DB1 has files at C:\Data
- DB2 has files at C:\Data
- DB3 has files at C:\Program Files\Data
The agent identifies C:\Data and C:\Program Files\Data as two filesets, and are uploaded sequentially. However, the files within a fileset are uploaded in parallel.
Differential backups
The Hybrid Workloads agent uses the Microsoft VDI to perform differential backups of MS-SQL databases. The amount of time taken to scan the changed data using Microsoft VDI is lesser than the VSS method leading to speedier differential backups. When you run a differential backup, the Hybrid Workloads agent backs up only the databases that have changed since the last full backup. Druva backs up the differential data and creates a recovery point in your storage. You can run a differential backup if a recovery point from the full backup already exists. In the absence of a recovery point from a full backup, the differential backup is converted into a full backup automatically. For more information, see Scenarios when the SQL differential backups get converted to full backups.
Note: When you click Backup Now, a differential backup is triggered. However, if your server is getting backed up for the first time, a Full Backup is initiated. A manual backup is not restricted by the specified bandwidth. A manual backup uses maximum bandwidth available.
Important: For Druva to use the Microsoft SQL Server VDI for differential backups, ensure that:
- The MS-SQL agent on the SQL server is version 4.9.4-110537 or later.
- A full backup is successful after the SQL agent upgrade.The differential backup after this full backup will use the VDI backup method.
- A full backup is scheduled in your SQL backup policy. If your SQL backup policy only has differential backups, the differential backups will continue to use the Microsoft VSS method for backups.
Understanding recovery points created using a differential backup
A recovery point created using a differential backup works similar to a full backup job in the way that it creates a recovery point that you can use to restore your database. Since a differential backup job can be faster in execution in comparison to a full backup job, you can schedule multiple differential backups in between full backups.
Continuing from the previous example, let us assume that you have specified daily differential backups at 9:00:00 PM. Between February 1, 2017, and February 10, 2017, 10 differential recovery points are created. When you try to restore your database using recovery points on February 11, 2017, at 5:00:00 AM, you can see 12 recovery points (2 recovery points from the full backup and 10 recovery points from the differential backups) under warm recovery points. Differential recovery points are also retained based on the daily, weekly, monthly, and yearly retention periods.
The advantage of a differential backup is the backup job speed. A differential backup job is faster than full backup since the agent directly gets information about the updated database from the SQL server.
Restoring from a recovery point created using a differential backup
If you are restoring your database on February 13, 2017, at 11:00:00 AM,
- The recovery points after differential backups on February 1, 2017, and February 2, 2017, are purged.
- In the warm recovery points, you can see v after differential backups created starting February 3, 2017, through February 12, 2017.
- You can see recovery points created after full backup on February 1, 2017, and February 8, 2017.
Since all the recovery points above fall under warm recovery points, you can select any recovery point as a recovery point, and use it to restore your database. However, when you select a recovery point created after a differential backup, Druva uses a full backup recovery point created right before it. Typically, full backup recovery point created on February 1, 2017, is purged based on 10 day retention period. But when you select a differential recovery point created before February 8, 2017, for restore, Druva requires the full backup recovery point created on February 1, 2017. Since there are differential backup recovery points that are retained and are tied to the February 1, 2017, recovery point, the February 1, 2017 recovery point is retained.
When you select a recovery point that has a VDI differential backup recovery point and choose to Restore database files, the SQL agent creates a temporary database named Rst_<database name selected for restore>. The agent then uses the .mdf, .ldf, and .ndf files from the VSS full backup recovery point and attaches them to this temporary database. Finally, the agent runs SQL commands to restore the .bak data from the VDI differential backup recovery point over this temporary database. Once this process is successful, the SQL agent downloads the updated .mdf, .ldf, and .ndf files on the selected server and deletes the temporary database.
Note:
- You can restore the .mdf, .ldf, and .ndf files to servers with SQL agent version 4.9.4-110537 and later. Servers with older agents will not be available in the Select Server dropdown in the restore settings while restoring database files via the VDI restore option.
- Older recovery points that have VSS full and differential backups will restore database files (.mdf, .ldf, and .ndf files) directly without creating a temporary database (rst_DatabaseName).
Workflow
A differential backup contains the following steps:
- Druva checks if the agent is running. If the agent is not running, Druva queues the backup request. The request is executed after the Hybrid Workloads agent is up and running.
- The Hybrid Workloads agent initializes Microsoft VDI on the SQL server. The SQL server then freezes the I/O on the selected databases.
- The Hybrid Workloads agent then fetches the differential data (data changed since the last full backup) from the SQL server through the VDI interface.
- Druva uploads the differential data to the server. Once all the files have successfully uploaded to the server, the backup is marked successful.
Scenarios where Druva converts SQL differential backups to full
Druva converts differential backups to full backups, if:
- A differential backup of a database for which a full backup is not complete is attempted.
- A new database file is added to or deleted from a database since the last backup.
- A database file is renamed or moved since the last backup.
- A database was renamed.
- Inconsistencies between the uploaded database files and its metadata are detected.
- The master database was included in the last full backup, and the path or name of the master database files changed since the last full backup.
- Druva cannot obtain details about data change from the Volume Shadow Copy Service.
- A full backup fails, then the next differential backup will be converted to a full backup.
- If a full backup is executed by Druva MS-SQL agent and the second full backup is been executed by a third-party backup tool or MS SQL server. Then Hybrid Workloads agent can convert next differential backup to full backup.
- If a database is encountered as shrunk since last full/differential backup, Druva converts the subsequent differential backups to full backups.
- Druva cannot take a differential backup on a secondary node of an availability group. In such a case, Druva runs a full backup.
- If a database is moved, deleted, or added to a backup set, Druva converts the next differential backup for all the affected backup sets to full.
- If there is a discrepancy in the backup start time between the MS SQL server and the Druva MS SQL records, Druva converts a differential backup to a full backup.
Transaction log backup
Transaction log in MS-SQL server records all the updates to the servers. Druva frequently backs up the transaction log based on the intervals you provide in the backup policy, and are triggered after a full or differential backup is complete. When Druva backs up transaction logs, transaction logs are truncated on the MS-SQL server. If a full backup is not complete for a server even once, the transaction log backups are not triggered. Transaction logs provide a tighter recovery point objective and are dependent on recovery points created using the full or differential backup. Log backups are not applicable for databases in simple recovery mode.
Understanding log backup schedules
Backed up transaction logs are retained based on daily retention period. Weekly, monthly, and yearly retention policies are not applicable for log backups.
For example, you specify an interval 30 minutes for log backups. In the example above, the full backup is triggered on February 1, 2017 at 12:00:00 PM, and completes on February 1, 2017 4:00:00 PM. At 4:30 PM, a log backup is triggered. Subsequently, the transaction log is backed up every 30 minutes until 9:00:00 PM when differential backup kicks in.
Restoring from a transaction log
When you restore your database using a transaction log, you can:
- Choose a point-in-time when a transaction occurred
- Choose a marked transaction in the transaction log and restore your database to that point.
- Choose a point-in-time when a transaction occurred and leave the database in standby mode
When you choose a point-in-time or a marked transaction, Druva restores your database using a recovery point. After restoring your database using a recovery point, it applies transaction logs to your database up to the selected transaction. This lets you restore your database to a time between two recovery points, allowing a tighter recovery point objective.
Workflow
The following flowchart depicts the transaction log workflow:
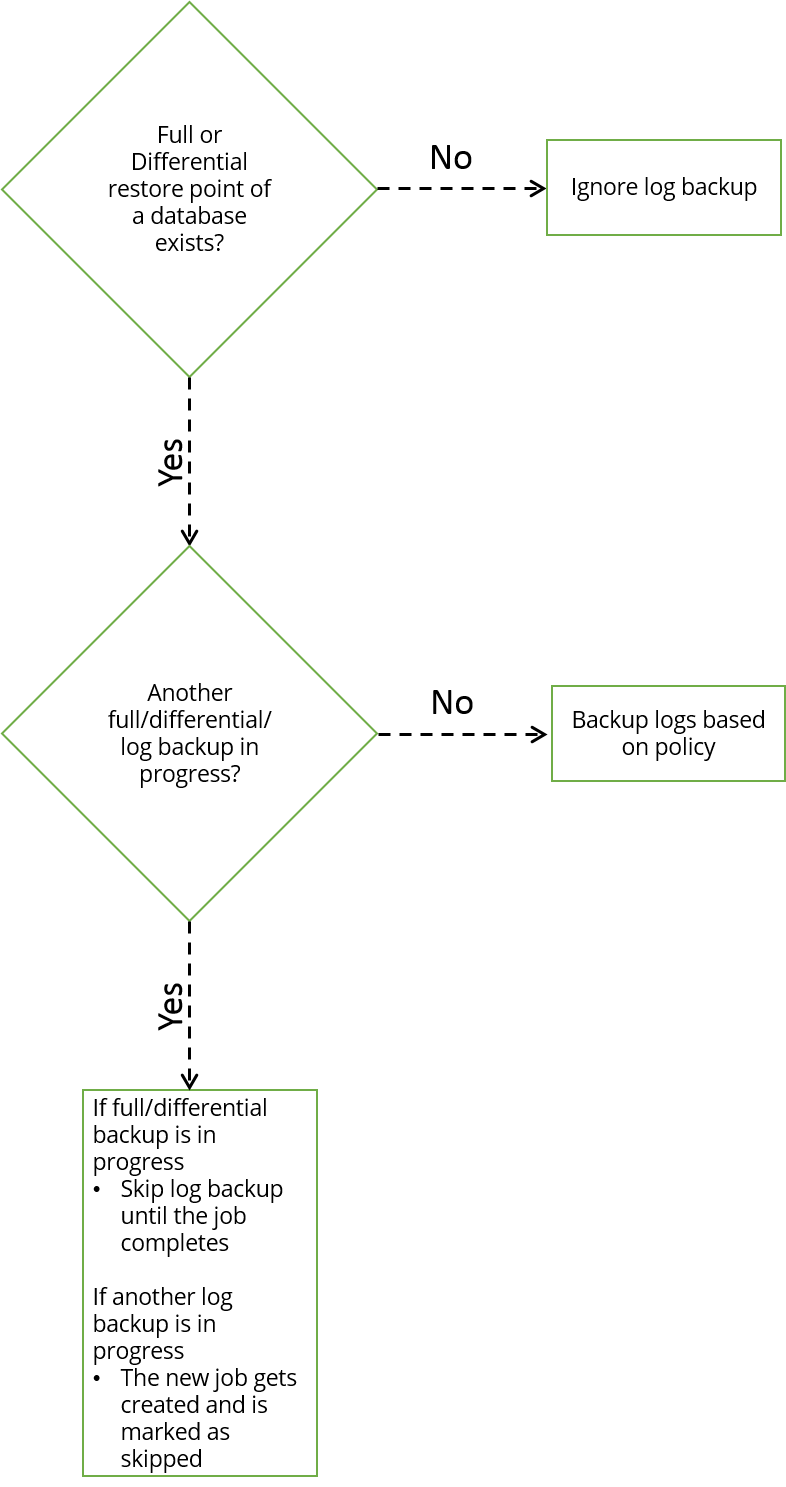
Limitations on transaction mark backup and restore for AG backup sets
Druva does not back up transaction marks if the log backups are taken from any secondary nodes.
MS-SQL server does not replicate transaction marks related to the transaction logs on the secondary nodes for databases in availability group (AG). If you try to restore a transaction mark for an AG backup set from Druva, you might or might not see transaction marks that were created on the MS-SQL server depending on whether the log backup happened from the primary or secondary node.
SQL Tail-Log backup
A tail-log backup is a transaction log backup where the log records that have not been backed up are captured. This prevents data loss and maintains the log chain sequence.
SQL Tail-Log backup can be used in the following scenarios:
- If you were planning to shut off a database at one location, and then restore it on a different server, then you can initiate a tail-log backup before you shut down the database. The term tail implies that it is the end of the log backup sequence, and therefore ensures that there is zero data loss and a chain for the restore operation is maintained. If a tail-log backup is not initiated, all the transactions that happened after the last log backup are lost.
- If the database fails to start or goes offline, then you may want to restore the database immediately. Before recovering the database, perform the tail-log backup. It can be initiated regardless of when the last t-log backup was performed.
For more information, see Restore original database.
Next step
After your databases are backed up, you can restore them if a recovery is required. For more information on restore jobs, see: