Druva disaster recovery workflow
Enterprise Workloads Editions
❌ Business| ✅ Enterprise (Purchase Separately) | ✅ Elite
Disaster recovery stages
The following table lists the different stages of the disaster recovery process.
For definitions of different terms and concepts used, see Disaster recovery concepts.
| Stage | Description |
|---|---|
| Restore |
With Disaster Recovery, the Druva AWS proxy:
|
| Failover |
The Druva AWS proxy replicates the entire virtual machine the first time it creates a DR copy. Subsequently, it incrementally updates the DR copy based on the replication frequency specified in the DR plan. This DR copy replaces the copy that is present in your AWS account. Druva AWS proxy maintains only the latest DR copy of a virtual machine. At the time of failover, the Druva AWS proxy:
|
| Failback | You can failback the EC2 instances (failed over) and recover the virtual machine with a single click in your virtualization infrastructure in a few hours after it has been recovered to your AWS account during failover. |
The following diagram depicts the Disaster Recovery workflow:
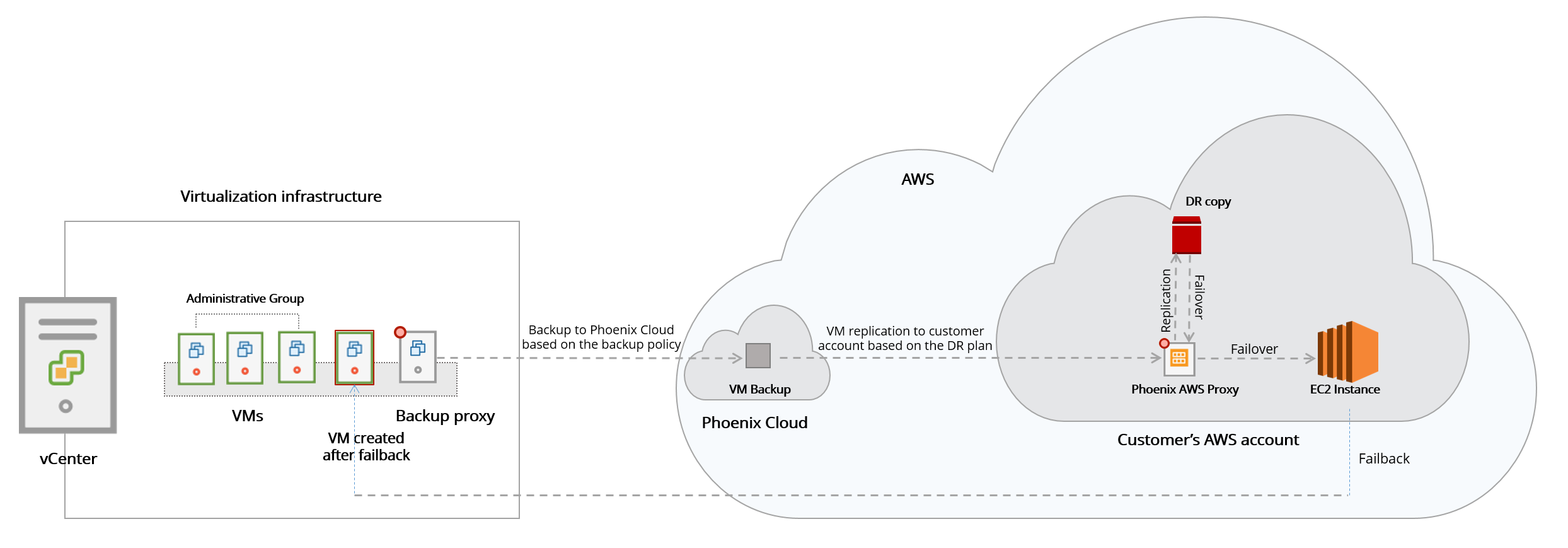
How disaster recovery works
Disaster Recovery solution takes advantage of the backups of the data center to the Druva Cloud. The DR Backup site is deployed in the customer’s AWS account and since Druva is also deployed on AWS, data transfer between the accounts in the same region is seamless.
The latest backup recovery point is copied into your AWS account and stored as writeable snapshots.
The same process is repeated for all VMDK disks attached to the protected VMs.
But how is it happening, you might ask? The entity executing all these tasks is the Druva AWS proxy. The Druva AWS proxy moves the data from Druva S3 to the customer’s account but to make this transition happen, the EC2 instance running the Druva AWS proxy needs a set of permissions. These permissions are defined in the Druva role and policy added to the customer account during proxy deployment.
In a nutshell, this process is the data path from the primary data center to the backup site in the cloud. The frequency of the updates is configurable in Druva and it should be set according to the required RPO.
For more information on DR plans and creating DR plans, see Disaster Recovery Plan.
Restore workflow
Let's discuss the DR restore workflow flow briefly and know what is happening during the process of copying data from Druva account to the customer account.
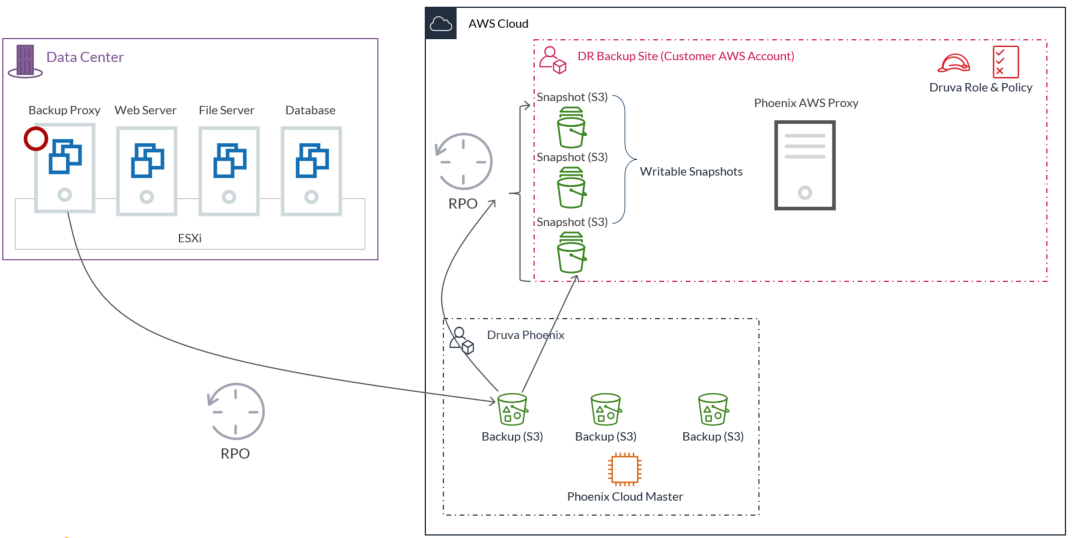
- The Druva Cloud tells the Druva AWS proxy to copy the virtual machine backup data from S3 bucket in Druva.
- The Druva AWS proxy then makes an API call to execute this command.
- The data from S3 goes through the Druva AWS proxy to the writable snapshot and the data path for this Druva AWS proxy is the Internet gateway.
We introduce one more entity here, which is S3 endpoint. It ensures that the data coming from one account to another does not leave the AWS network if you are using PrivateLink..
Failover workflow
To ask what a failover is, is to ask what happens when disaster strikes and the primary data center becomes unavailable. Here’s what happens.
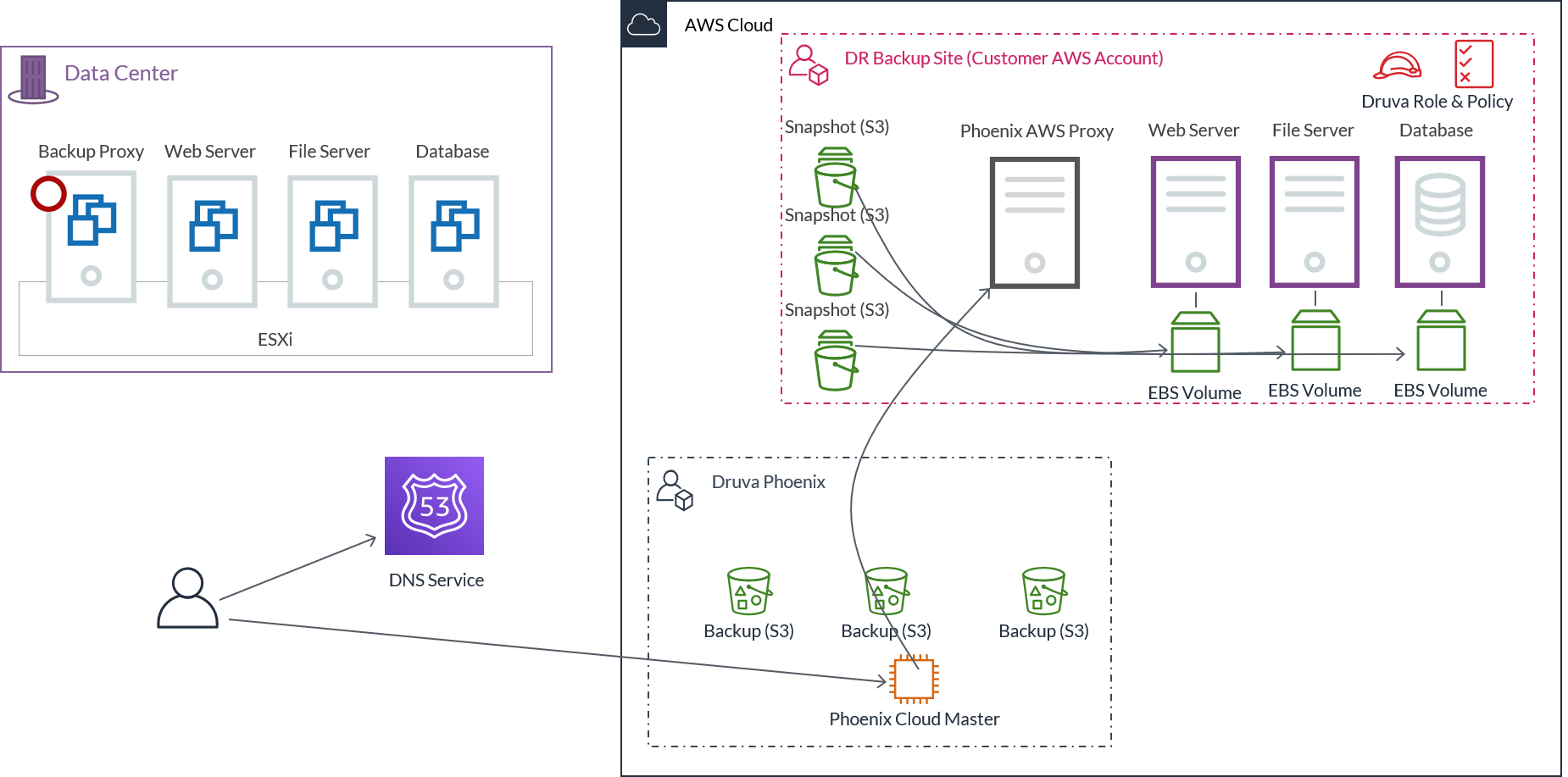
- First, an administrator triggers the failover from the Management Console and Druva Cloud instructs the Druva AWS proxy to initiate the failover.
- The EBS snapshot is used to create an EBS volume. The Druva AWS proxy creates an EC2 instance in your AWS account. You can choose the EC2 instance type from the Management Console or let Druva automatically assign the instance type (recommended) when you configure the VM for DR. The EBS volume gets attached to the EC2 instance.
- Once the process has completed, EC2 instance is restarted and is ready to support its workload. The same process is repeated for all protected VMs.
- The last step is to update the DNS servers to redirect the traffic to the IP addresses of the new EC2 servers. This can be achieved via post-boot scripts.
Druva provides advanced orchestration capabilities allowing to decide on the failover sequence, creating dependencies between EC2s and adding scripts for execution during EC2 boot. An example of dependency would be an e-commerce Web server storing data in the database. It wouldn’t make sense to start Web EC2 before the database is available.
Disaster Recovery also allows for DR testing in a different VPC or subnet.
Failback workflow
The starting point for failback is a freshly rebuilt primary data center and backup DR site containing data which needs to be transferred back to the primary site.
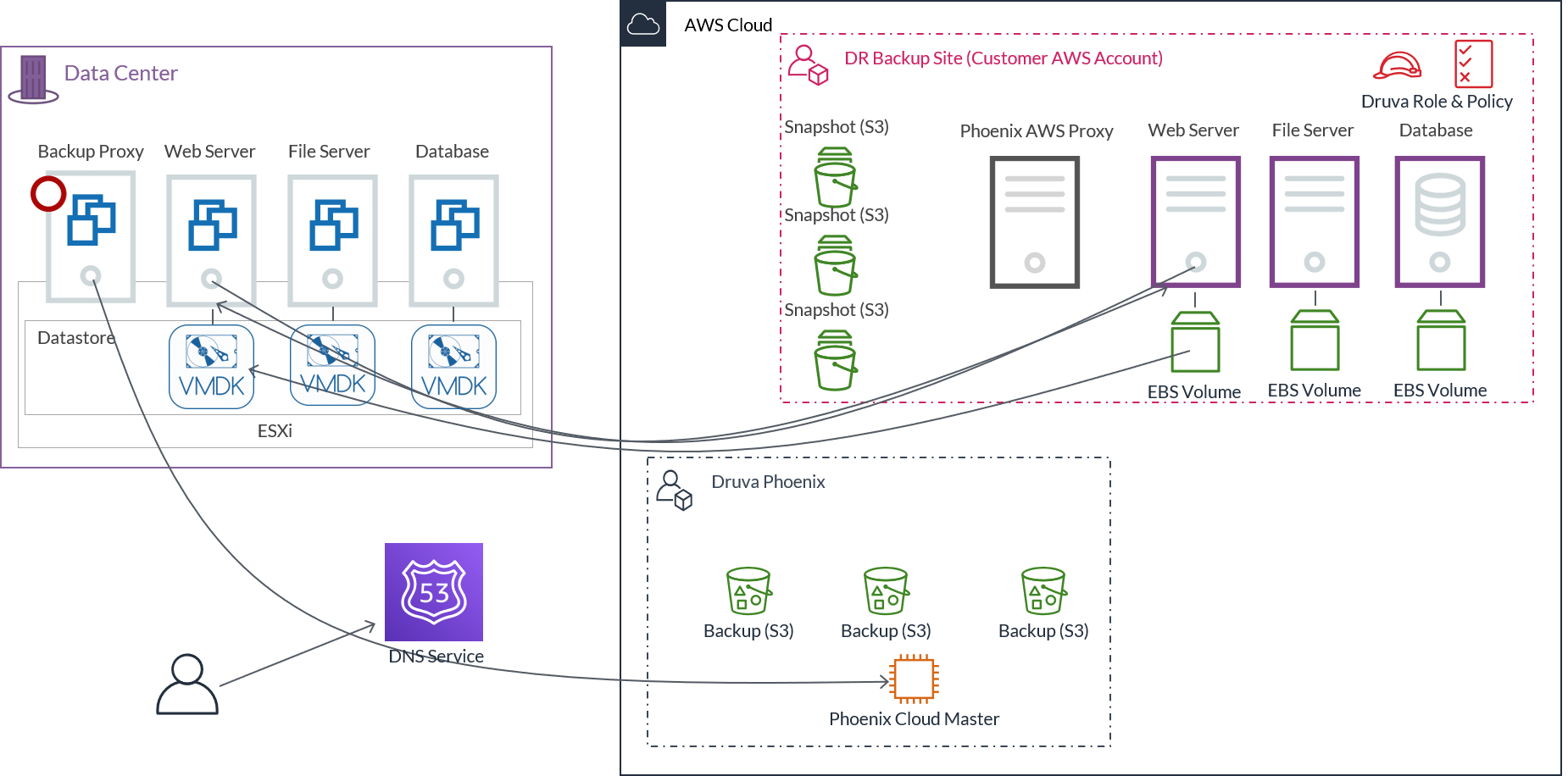
- The first step is to redeploy the Druva backup proxy VM to establish communication with the Druva Cloud and get the backup configuration from the cloud.
- In the next step, the backup proxy launches a template VM, which reaches out to the EC2 instance and get its configuration information – number of CPUs, memory size, number of disks, and so on.
- Based on this information received, it attaches one or more VMDK disks and starts copying data from the EBS volumes to the VMDK disks.
- Once the download is completed, the template VM is rebooted with the configuration parameters read from the EC2 instance. After that, the server is operational. The same process is repeated for all protected VMs.
- The last step is to update the DNS to redirect the traffic back to the primary site.