File server FAQs
 Business Enterprise Elite
Business Enterprise Elite
This topic consists of the following sections:
Overview FAQs
► What does Druva back up?- Druva provides support for several file types, out-of-the-box. To see the full list of files that Druva backs up, see Default file types for backup.
Supportability FAQs
►What server operating systems does Druva support for the File server?-
Druva supports Windows and Linux operating systems for File servers. For more information about the supported operating systems, see File server support matrix.
►What file systems does Druva support?-
Druva supports file and folder backup of the following file systems:
- On Windows: NTFS and ReFS
- On Linux: EXT3, EXT4, and XFS
Note: Druva also supports the backup of files and folders on the non-VSS partitions such as FAT, FAT32, and exFAT.
►Does Druva support data deduplication on NTFS and ReFS?-
Yes, Druva supports data deduplication on NTFS and ReFS, however, it does not support back up of the extended attributes, such as encryption and compression.
►What file types, by default, Druva support for the File server?-
Druva provides support for several file types, out-of-the-box. To see the full list of files that Druva backs up, see Default file types for backup.
►Does Druva support both on-premise and cloud infrastructure to backup and recover File Servers?-
Yes, Druva supports backup and restore of File Servers running on the on-premise physical and virtual infrastructure, as well as cloud infrastructure such as Amazon EC2, Azure VMs, Google Compute Engines, and so on.
►How does Druva protect the File Servers workloads on Microsoft Azure?-
Druva supports agent-based backup for files that enables you to leverage File Server agent and deploy it in any of the supported Operating Systems on an Azure VM and protect these workloads. Configuration and backup/restore workflows remain the same whether data is located on-premise or on any Cloud like Azure. Another added advantage is that you can restore the data to any target residing either in the customer’s data center or private or public cloud.
You can use NAS proxy to protect files as long as the standard SMB/NFS protocols are available. If the files reside on a VM, then we can leverage the File Server agent to protect the files.
Configuration FAQs
►What do I need to know before performing a configuration of my File servers?-
Before configuring your File servers, we recommend that you read File server configuration checklist. This checklist should help you perform a configuration that is best suited for your environment.
►How do I deploy Druva File server?-
After you buy a license, you must deploy Hybrid Workloads agents for the File server. For more information, see Deploy Druva File server agent.
►How do I configure my File servers for backup?-
Getting your File servers ready for backup is simple. For more information about how to configure File servers for backup, see Configure Druva to back up File servers.
Backup and restore FAQs
►I have enabled smart scan, what ACLs will be restored when I restore data in the middle of a month?
-
Consider a scenario where the following recovery points are created after two backups on the File server:
- R1 - Created after the first full backup.
- R2 -Created after the subsequent backup with the smart scan.
Druva restores file data in one of the following ways:
- If file data is not changed after R1: Druva restores data from R2 and the ACLs are restored from the last full backup, which is R1.
- If file data is changed after R1: Druva restores data and ACLs from R2.
►What will be the effect on backup if we change the IP address of the file server?-
There will be no effect on the backup as Druva does not use IP address as a unique identifier for backups.
►Can Druva perform a File-level backup of the Windows drives A:\ and B:\?-
A:\ and B:\ drives (or drive letters) are usually reserved for floppy disk drives. If the device does not have a floppy disk drive, the drive letters A and B can be assigned to volumes.
Hybrid Workloads agent checks whether a drive is fixed or removable and ignores all the removable drives. Since A:\ and B:\ are removable drives by default, Druva ignores their backup.
►What type of backups does Druva perform on File servers?-
The first backup of your servers is a full backup. Thereafter, Druva performs an incremental backup of all File servers.
►How do I view the files that were missed or skipped during the backup?- Download the log folder and open the ‘Phoenix-
-MissedFiles.log’ file to view the list of files that were skipped or missed during the backup operation.
►What does Druva exclude from backup?-
By default, Druva excludes some file types from backup. To see the full list of files that Druva excludes, see Default folder exclusions.
►How do I back up or restore my data?-
To know how to back up your File servers, see Back up File servers. To know how to restore your File servers, see Restore File servers.
►How does Druva back up or restore my File server data?-
- To understand the workflow at the time of backup, see File server backup workflow.
- To know how Druva restores your File server data, see File server restore workflow.
►I want to run a backup job manually. How do I do that?-
After you configure your servers, Druva performs a backup of your servers according to the backup policy that you set at the time of configuration.
In addition to the scheduled backups, you can start a backup at any time. After these backups complete, the next backup from the File servers follows the schedule defined in the backup policy.
Procedure
- Log in to the Management Console.
- On the menu bar, click All Organizations, and select the required organization from the drop-down list.
- On the menu bar, click Protect > File Servers.
- In the Registered Servers page, under the Server Name column, click the server name.
- In the server details page, under the Configured Backup Sets section, select the backup set, click more options, and then click Backup Now.
Note: The first Backup Now will always trigger a full backup for File server and MS-SQL server. The subsequent Backup Now requests will trigger an incremental backup for File server and Differential Backup for MS-SQL server.
For more information on Differential Backup, see Differential backups.
►What are the benefits of enabling smart scan?-
Smart Scan applies to backups of SMB and NFS shares that have:
- Files and folders that are infrequently modified
- Archive or log data
When a large number of infrequently modified files and folders are configured for backups in a backup policy, backups can take long because the Hybrid Workloads agent scans every file and folder. Enabling Smart Scan for these backup sets can save a lot of time by skipping infrequently modified files and folders.
-
Note: The smart scan applies to Linux servers, NAS shares and Windows servers (only UNC shares)
►Management Console displays a different count of source data scanned than the actual files.-
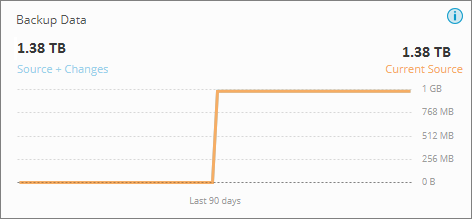
The Job Details page may show a different count of the source data scanned for a backup job than the actual files being backed up as shown in the following screenshots:
Backup Data section on the Dashboard screenshot:
Job Details page screenshot:
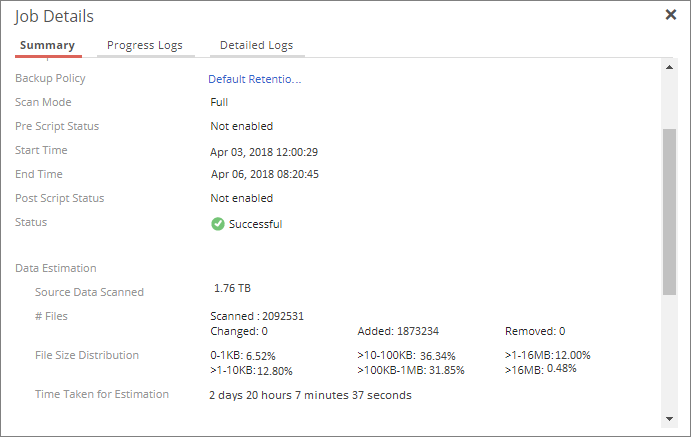
In the above screenshots, the Backup Data section on the Dashboard depicts that Druva backs up 1.38 TB data although it scans 2092531 files of 1.78 TB source data as shown in the Job Details page screenshot.
Druva implements folder walk or USN walk to scan files for backup. In a nested file structure, the count of the scanned files is always greater than the estimated files. For example, to scan 10K files at the ninth folder level, Druva scans the nine folders along with the files and folders contained in the folders, and 10k files that result in the scanned count greater than the actual files. In a USN walk scan, the count of scanned files comprises the USN event count for the volume.
The count of the source data scanned also differs if the network disconnects when the data is being uploaded to the cloud. During the next reconnection, the respective data is scanned again and uploaded. This results in an additional count of the data scanned.
Additionally, the count of the source data scanned may differ if you have not excluded the /proc folder from the backup configuration. The /proc folder contains ever-changing files. Because the file creation is dynamic, the Hybrid Workloads agent continues to estimate the file content. The sparse file blocks are also a part of the /proc folder, which leads to incorrect estimation statistics. Therefore, ensure that you exclude the /proc folder from the backups.
►Management Console displays a different ‘Last Updated' date for ‘Data Profile’ and ‘Data Distribution’ on the File Backup Sets summary page.-
The File Backup Sets Summary page may show different 'Last Updated' dates in the Data Profile and Data Distribution cards.
.png?revision=1)
In the above screenshot:
Data Profile (Source + Change) Last Updated : Jun 29, 2023 17:43:53 and
Data Distribution Last Updated : Jun 07, 2023 19:05:47
After a full scan backup, the date/time and other statistics in the Data Distribution and Data Profile cards are updated. However, during an incremental scan, the date/time and statistics get updated only in the Data Profile card and not in the Data Distribution card.
Hence, the value of the date and time (Last Updated field) in the Data Distribution field mismatches the value in the Data Profile card.
►Is it possible to backup folders and files with periods ‘.’ ?-
Folders with a period at the end of their names cannot be created in Windows.
Filenames that start with a period are allowed, and these hidden files can be created, backed up, and restored like any other file.When working with Linux, folders or file names starting with a period (.) are considered hidden.
In either case (Windows or Linux), to ensure that you backup all files and folders on your server, including hidden ones and those with names starting with a period, select 'Backup All Folders' Option in the Content Rule of the Backup set.
-
-
Download the log folder and open the ‘Phoenix-<JobID>-MissedFiles.log’ file to view the list of files that were skipped or missed during the backup operation.