File server backup workflow
 Business Enterprise Elite
Business Enterprise Elite
This article provides the workflow diagrams and the steps for data backup from the following operating systems:
Note: If you restart or reboot your servers during backups, the backup operation is aborted. Hybrid Workloads agent starts a fresh backup following the backup schedule. Alternatively, you can start a manual backup at any time.
File servers with Windows operating system
This topic explains how data flow during data backup from the File servers with Windows operating system.
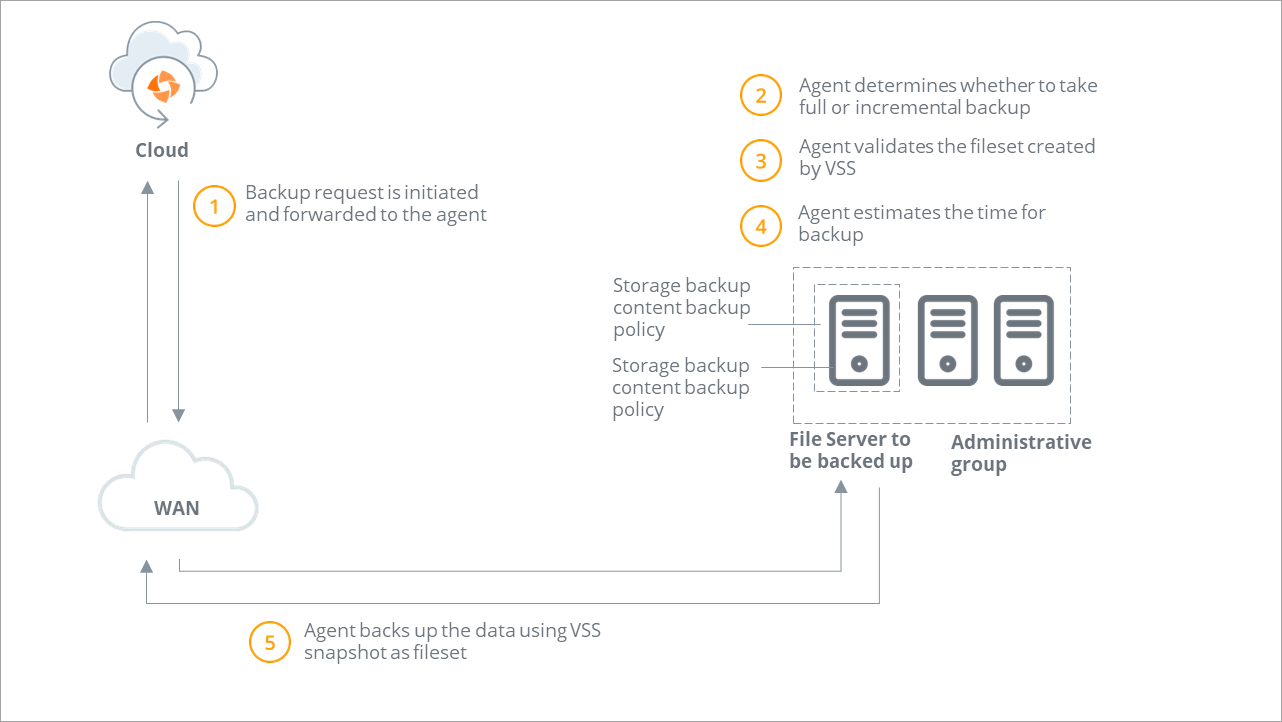
Backup workflow
| Step | Operation |
|---|---|
|
Step 1 |
A backup request is initiated and forwarded to the Hybrid Workloads agent. Druva checks if Hybrid Workloads agent is running.
|
|
Step 2 |
Druva determines the type of backup. If you or another administrator initiates the first backup, Druva performs a full backup. All subsequent backups triggered by administrators are incremental backups. |
|
Step 3
|
Hybrid Workloads agent verifies that the VSS service is running. If the VSS service is not running, Hybrid Workloads agent starts the VSS service and instructs VSS to create a recovery point. Hybrid Workloads agent validates if recovery points are created successfully. |
|
Step 4 |
Hybrid Workloads agent estimates the files and data to back up. |
|
Step 5
|
|
|
Step 6 |
After the backup completes, Hybrid Workloads agent deletes the created VSS recovery points. |
File servers with Linux operating system
This topic explains how data flow during data backup from the File servers with Linux operating system.
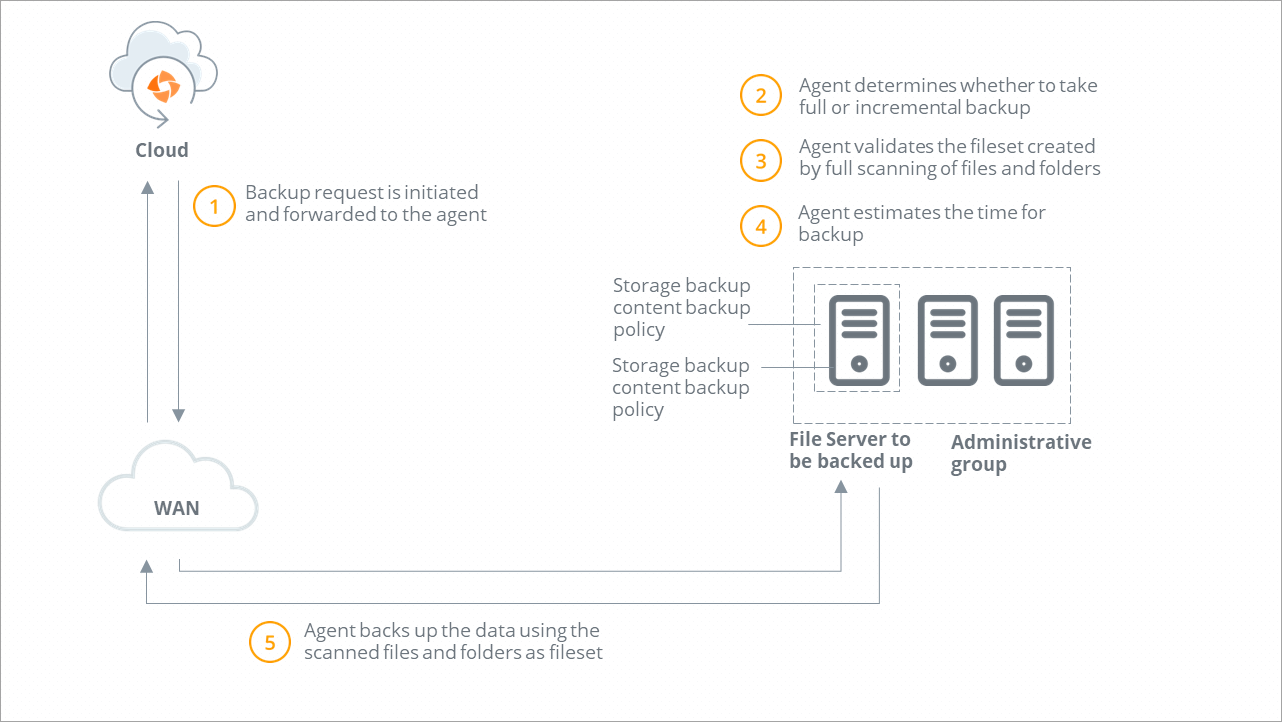
Backup workflow
| Step | Operation |
|---|---|
|
Step 1 |
A backup request is initiated and forwarded to the Hybrid Workloads agent. Druva checks if Hybrid Workloads agent is running.
|
|
Step 2 |
Druva determines the type of backup. If you or another administrator initiates the first backup, Druva performs a full backup. All subsequent backups triggered by administrators are incremental backups. |
|
Step 3 |
Hybrid Workloads agent performs the full scanning of live files and folders on the File server. |
|
Step 4 |
Hybrid Workloads agent estimates the files and data to back up. |
|
Step 5 |
Hybrid Workloads agent uses the scanned folders and files as the fileset for data transmission.
|