View Jobs
Overview
Druva CloudRanger provides an integrated view of all UI-triggered scheduled and maintenance activities on the Jobs page. Each job is identified by a unique Job ID and holds a specific status, and the job progress can be tracked via the progress log.
Jobs on Druva CloudRanger are categorized as follows:
To access Jobs, navigate to Monitor > Jobs from the top menu bar. The Backup jobs are displayed by default on the Jobs page:
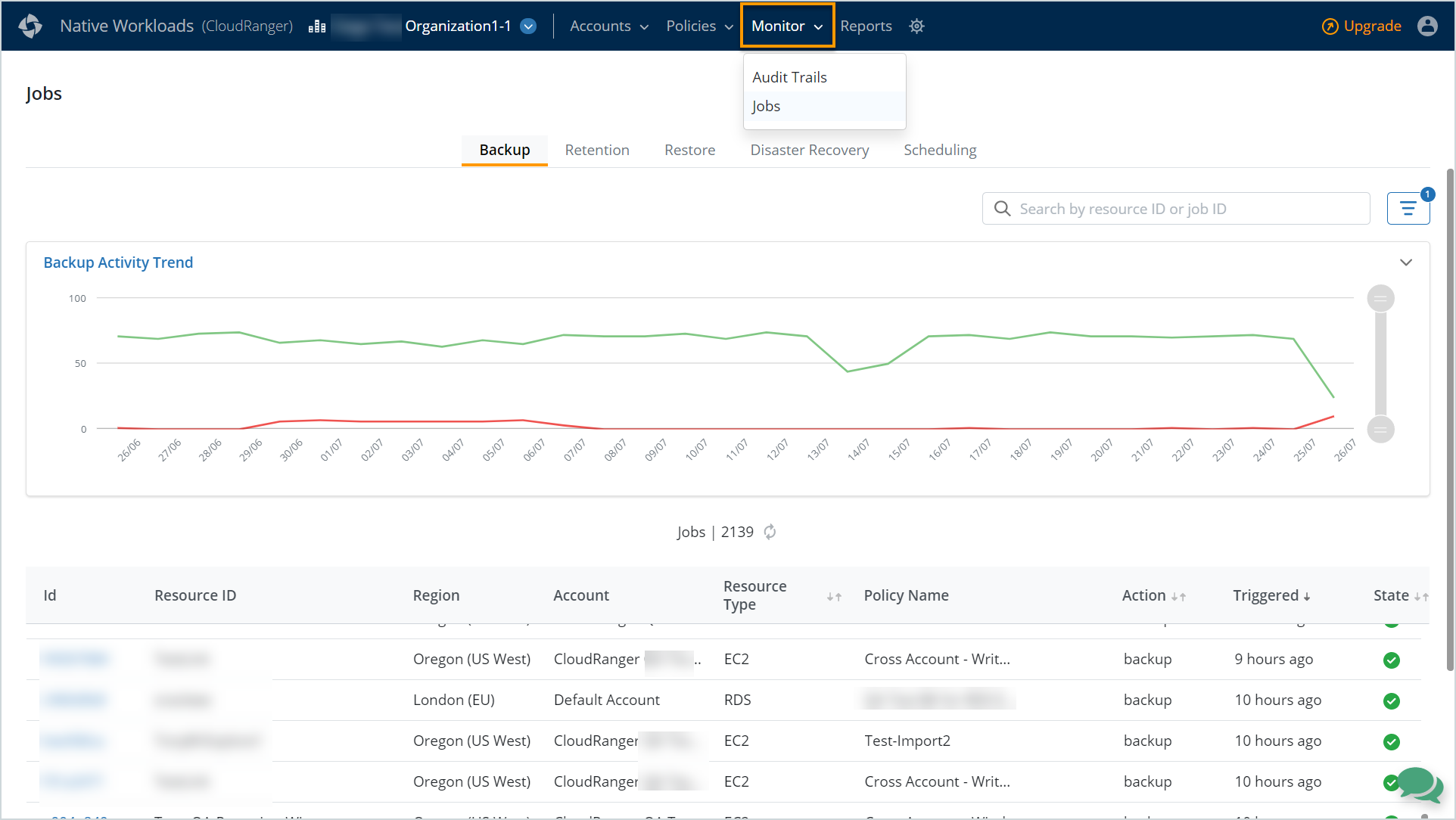
Click each tab to view jobs categorized by Backups, Retention, Restores, Disaster Recovery, and Scheduling.
Use the Search by Resource ID or Job ID text box to quickly locate a specific job. You can also use the filter icon to identify jobs by Region, Account, Resource Type, Policy/Plan Name, Action, Status, or by Date Range (for example, Jobs triggered in the Last 30 days).
- The Activity Trend chart provides a graphical view of all jobs within that category, in the last 30 days. Hover over the graph to view the total number of successful or failed jobs on a particular day.
- You can select a particular Job ID to view information on the backup and restore jobs, for example, to assess performance stats or troubleshooting, if required. The Job details page includes detailed information about the selected job, the job progress, and associated logs.
Filters
The job filters list the jobs based on their Region, Account, Resource Type, Status, and so on. You can apply one or more filters to view individual jobs and associated logs within the chosen job category.
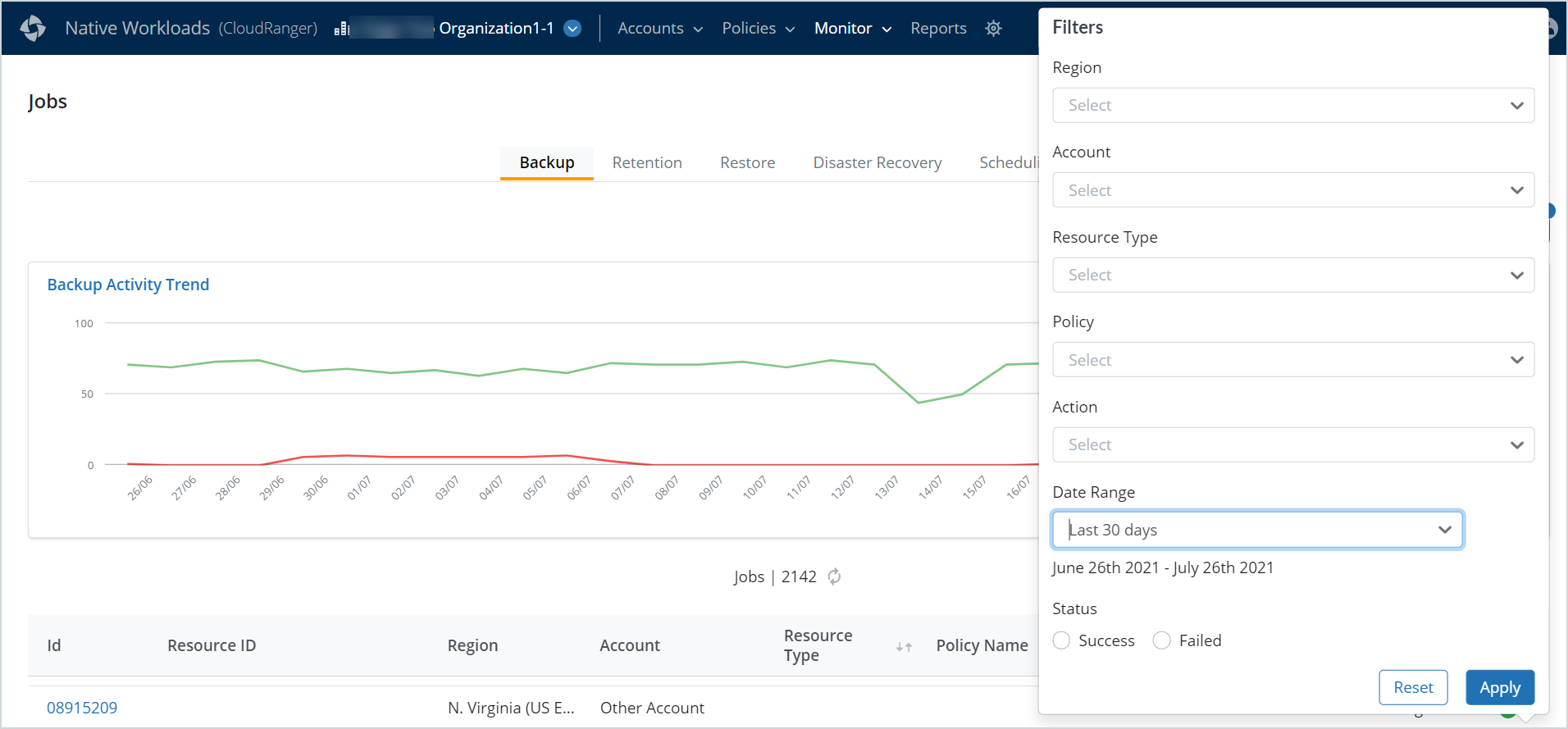
You can use one or more of the following filters:
- Region: Filter jobs triggered in a particular AWS region.
- Account: Select the CloudRanger Account on which a particular job is triggered.
- Resource Type: Select one or more resource types, for example, DynamoDB, EC2, RDS, or Redshift. You may also filter by all resource types.
Note: The Resource Type varies based on the job category selected. Disaster Recovery andScheduling jobs do not apply to DynamoDB resources.
- Policy: This filter applies only to Backup and Retention jobs. Select a backup policy to filter associated jobs.
- Plan Name: This filter applies only to Disaster Recovery jobs. Select a DR Plan Name to filter associated jobs.
-
Generated: This filter applies only to Backup jobs. Select Manually or By Policy to filter backup jobs generated manually or specify a backup policy. Use this filter to generate a list of backup jobs initiated manually or based on a policy-based schedule.
You can filter the backup jobs based on whether they were executed manually or via a policy-based backup schedule. The Generated filter allows you to select backup jobs initiated Manually or By Policy. If you select By Policy, proceed by selecting a backup policy to filter associated jobs. The existing Policy Name column will display the appropriate backup policy for backup jobs generated automatically.
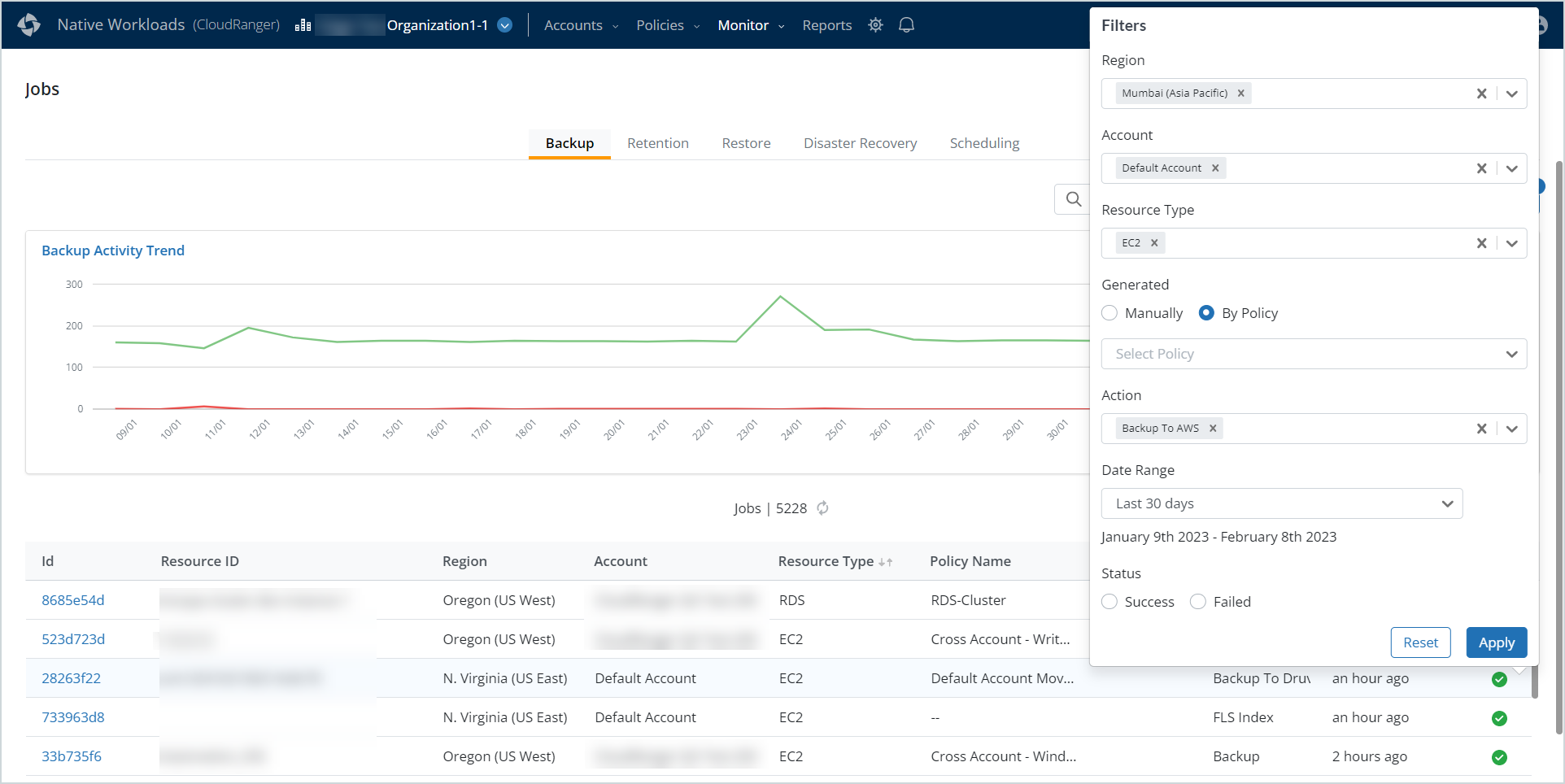
Note: Currently selecting Manually populates backup jobs initiated manually from February 13, 2023, and will exclude historical data (usually available up to 1 year prior). This is a known limitation.
-
Action: The options displayed in this field vary based on the job category selected. For example, you may apply the Plan Failover action to filter jobs initiated upon failover of a disaster recovery plan. The following Action filters are available based on the job category:
- Backup Jobs:
- Backup to AWS: Jobs initiated to backup AMIs and Snapshots to AWS
- Backup to Druva Cloud: Backup Jobs initiated to Druva Cloud
- EBS Archive
- FLS index
- S3 Archive
- Restore jobs: FLS Download and Snapshot.
- DR jobs: Environment Clone, Plan Failover, and Plan Failover Test.
- Scheduling jobs: Start, Stop, Reboot, and Resize ASG.
- Backup Jobs:
Note: The Action filter does not apply to Retention jobs.
- Date Range: You can filter jobs that were initiated in the:
- Last 24 hours
- Last 7 days
- Last 30 days
- Last 90 days
- Last 12 month
Note: The Jobs page is filtered to display only jobs triggered within the last 30 days, by default. You may choose to apply a different date range or disable the default filter to view all jobs triggered within the Last 12 months.
- Status: The Status filter allows you to filter jobs based on the job state. The current status of each job is displayed under the State column.
| Success |  |
| Failed |  |
Backup Jobs
Backup Jobs are displayed by default on the Jobs page. The Backup Activity Trend chart provides a graphical view of all retention jobs in the last 30 days. Hover over the graph to view the total number of successful or failed jobs on a particular day.
The backup jobs table displays the following information associated with each job:
- ID: A unique identification number associated with the backup job.
- Resource ID: The Resource associated with the backup job.
- Region: The AWS region in which a backup job is triggered.
- Account: The CloudRanger Account on which the job is triggered.
- Resource Type: The resource type on which the job is initiated, for example, DynamoDB, EC2, RDS, or Redshift.
- Policy Name: The backup policy associated with the job.
- Action: The type of action initiated by the job, for example, backup.
- Triggered: The time when the job was initiated.
- State: The current status of each job.
| Success | |
| Failed |  |
Note: A
Click a Backup Job ID to view the job details.
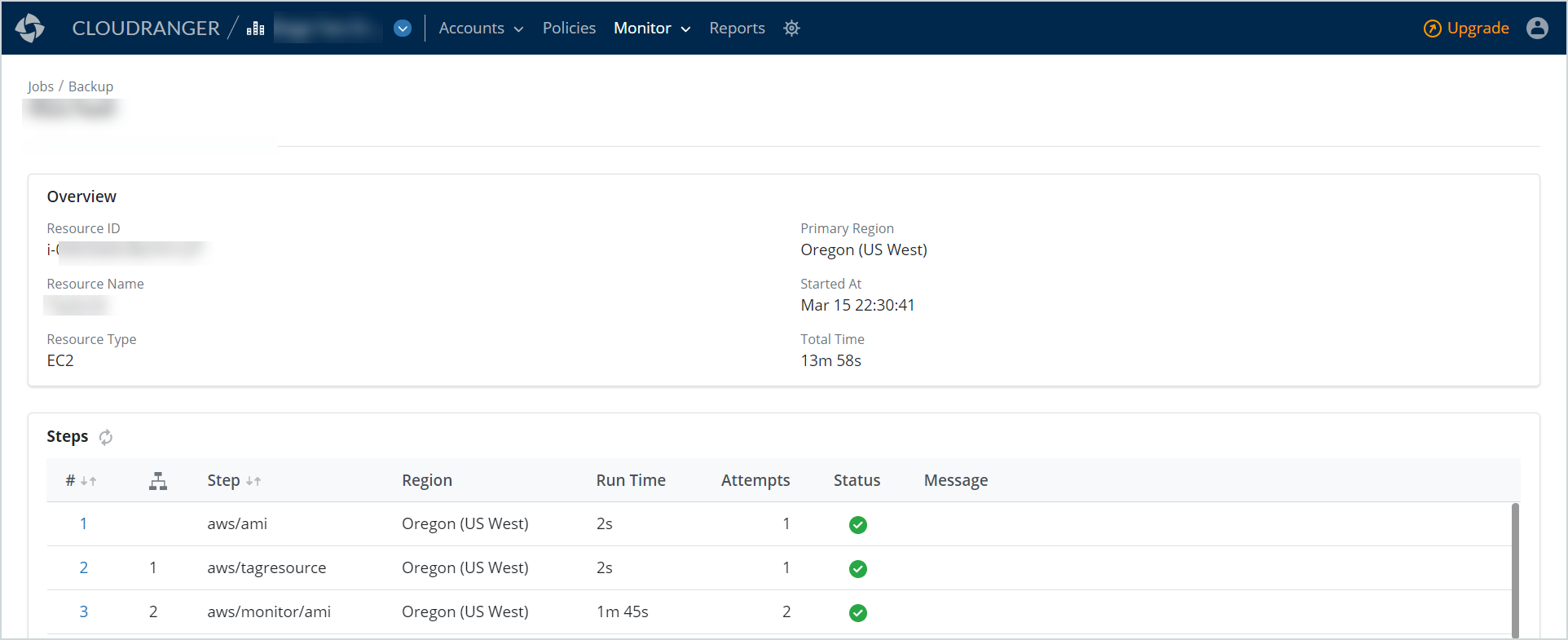
The backup job details page includes detailed information about the selected job, the job progress, and associated logs.
|
Field |
Description |
| Overview |
This section displays the following information associated with the backup:
|
|
Steps |
This section displays the stages in which the job is performed.
Note: The job steps allow you to assess each stage of the job, and the associated Messages, Run Time, and number of Attempts, in case of a failed job status. Use the Refresh icon to repeat a particular step on a failed job. |
Retention Jobs
Retention jobs are not resource-specific but are initiated in bulk for all snapshots and AMIs that need to be deleted. The Retention Jobs page lists all jobs associated with backup retention that were triggered within the previous 30 days.
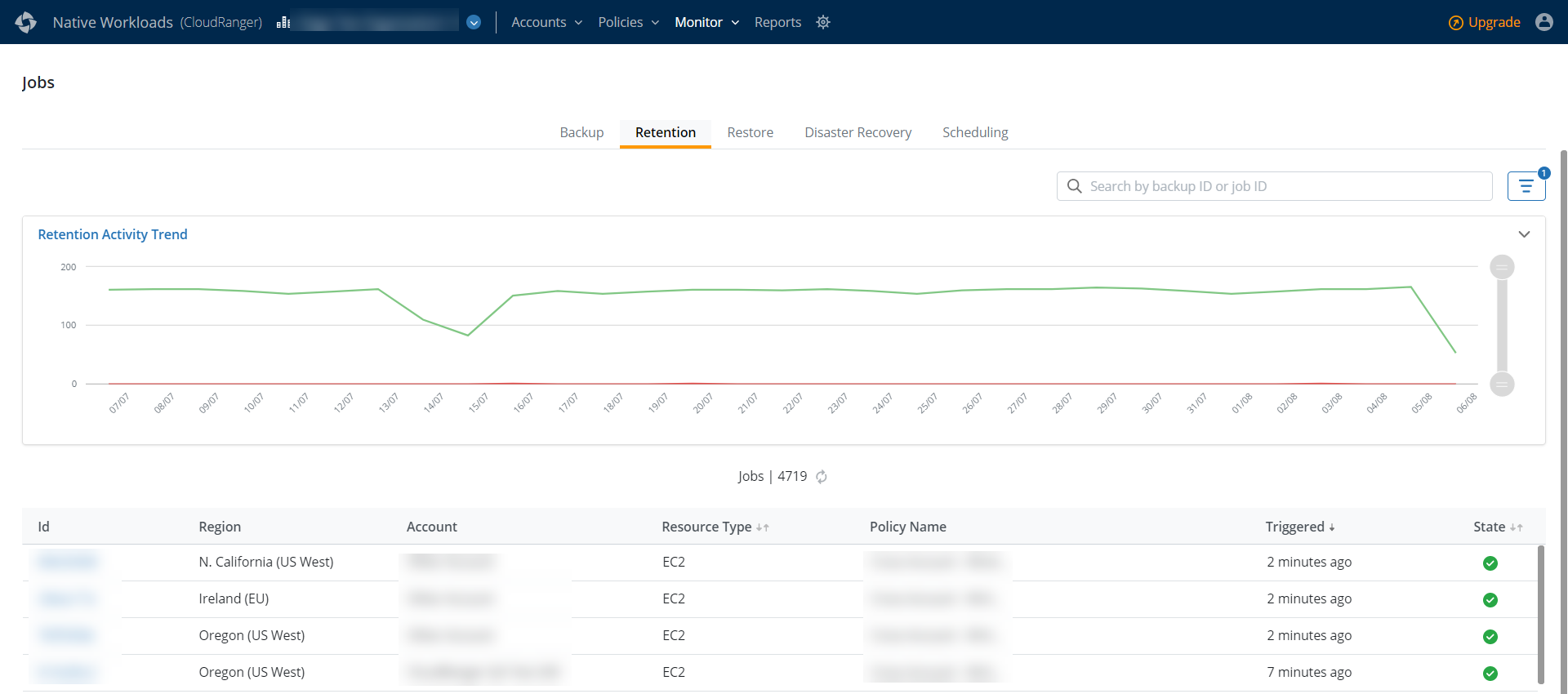
The Retention Activity Trend chart provides a graphical view of all retention jobs in the last 30 days. Hover over the graph to view the total number of successful or failed jobs on a particular day.
The retention jobs table displays the following information for each job:
- ID: A unique identification number associated with the job.
- Region: The AWS region in which a particular job is triggered.
- Account: The CloudRanger Account on which the job is triggered.
- Resource Type: The resource type on which the job is initiated, for example, DynamoDB, EC2, RDS, or Redshift.
- Policy Name: The backup policy associated with the retention job.
- Triggered: The time when the job was initiated.
- State: The current status of each job.
| Success | |
| Failed | |
Note: A
Click a Retention Job ID to view the job details.
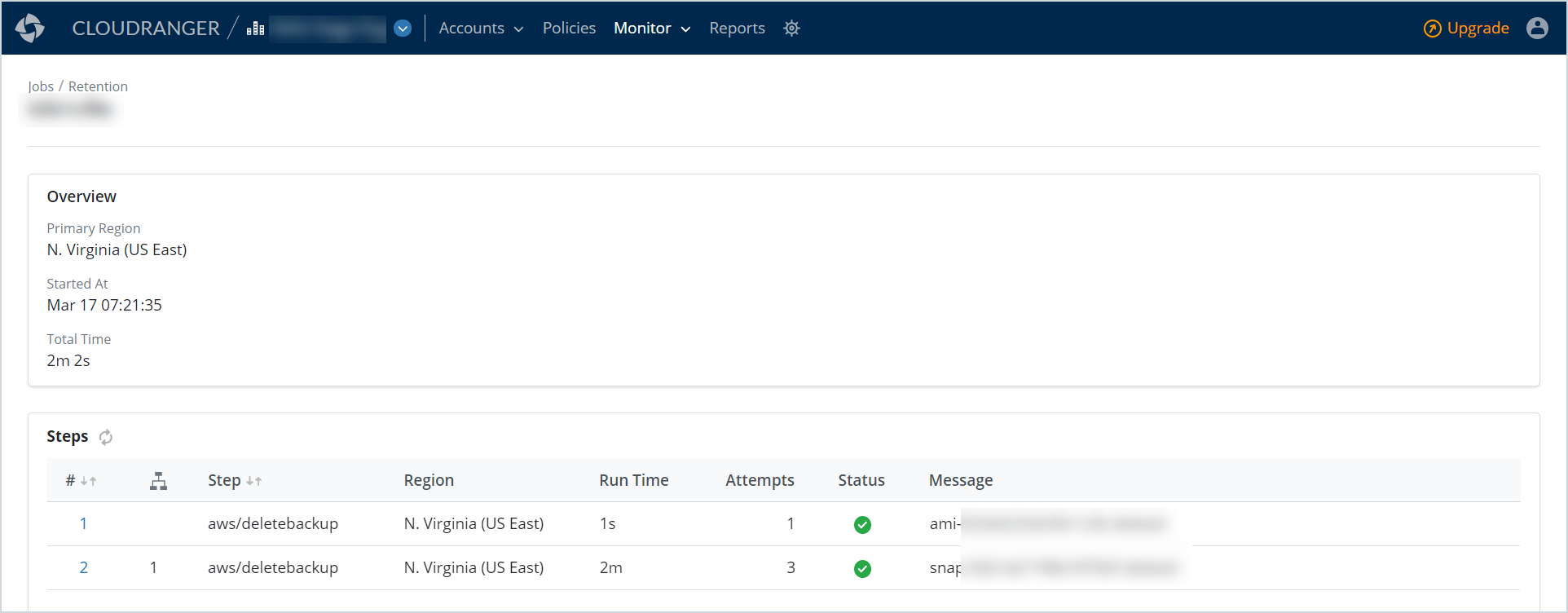
The retention job details page includes detailed information about the selected job, the job progress, and associated logs.
|
Field |
Description |
| Overview |
This section displays the following information associated with the retention:
|
|
Steps |
This section displays the stages in which the job is performed.
Note: The job steps allow you to assess each stage of the job, and the associated Messages, Run Time, and number of Attempts, in case of a failed job status. Use the Refresh icon to repeat a particular step on a failed job. |
Restore Jobs
The main Restore Jobs page lists all jobs associated with backup restore that were triggered within the previous 30 days.
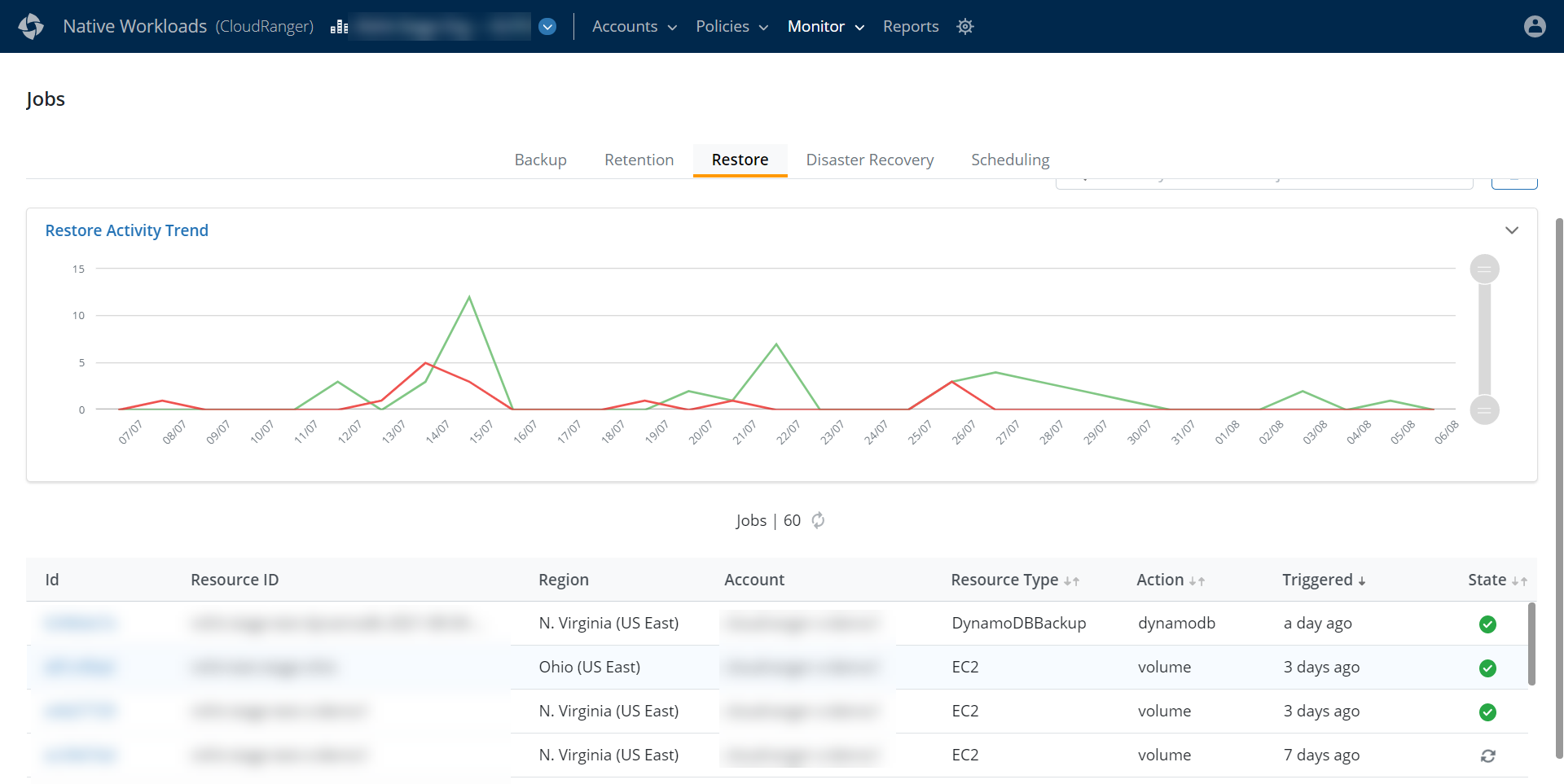
The Restore Activity Trend chart provides a graphical view of all restore jobs in the last 30 days. Hover over the graph to view the total number of successful or failed jobs on a particular day.
The main restore jobs table displays the following information for each job:
- ID: A unique identification number associated with the job.
- Resource ID: The Resource associated with the restore job.
- Region: The AWS region in which the restore job is triggered.
- Account: The CloudRanger Account on which the job is triggered.
- Resource Type: The resource type on which the job is initiated, for example, DynamoDB, EC2, RDS, or Redshift.
- Action: The type of action initiated by the job, for example, flsdownload.
- Triggered: The time when the job was initiated.
- State: The current status of each job.
| Success | |
| Failed | |
Note: A
Click a Restore Job ID to view the job details.
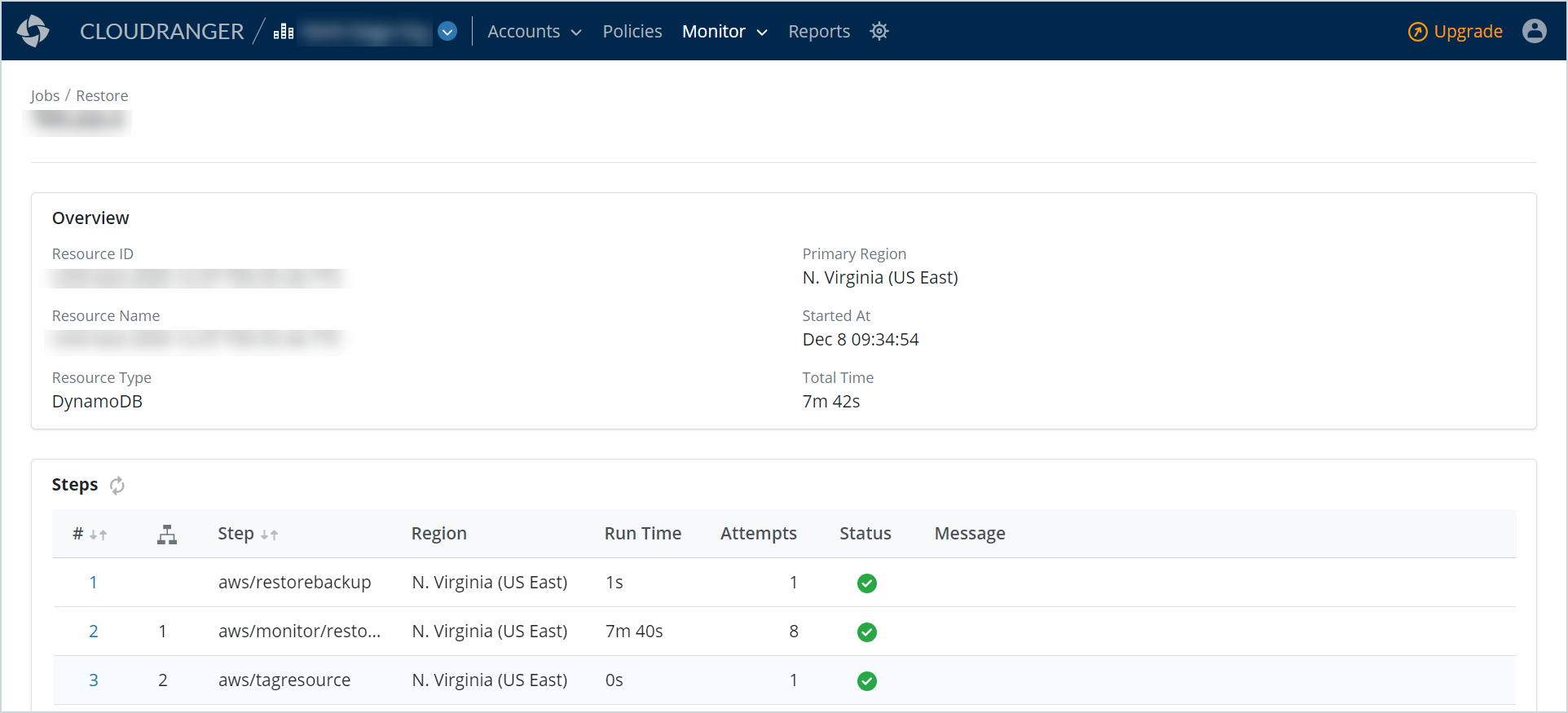
The restore job details page includes detailed information about the selected job, the job progress, and associated logs.
|
Field |
Description |
| Overview |
This section displays the following information associated with the restore:
|
|
Steps |
This section displays the stages in which the job is performed.
Note: The job steps allow you to assess each stage of the job, and the associated Messages, Run Time, and number of Attempts, in case of a failed job status. Use the Refresh icon to repeat a particular step on a failed job. |
Disaster Recovery Jobs
The main Disaster Recovery Jobs page lists all DR-related jobs, including environment cloning jobs, which were triggered within the previous 30 days.
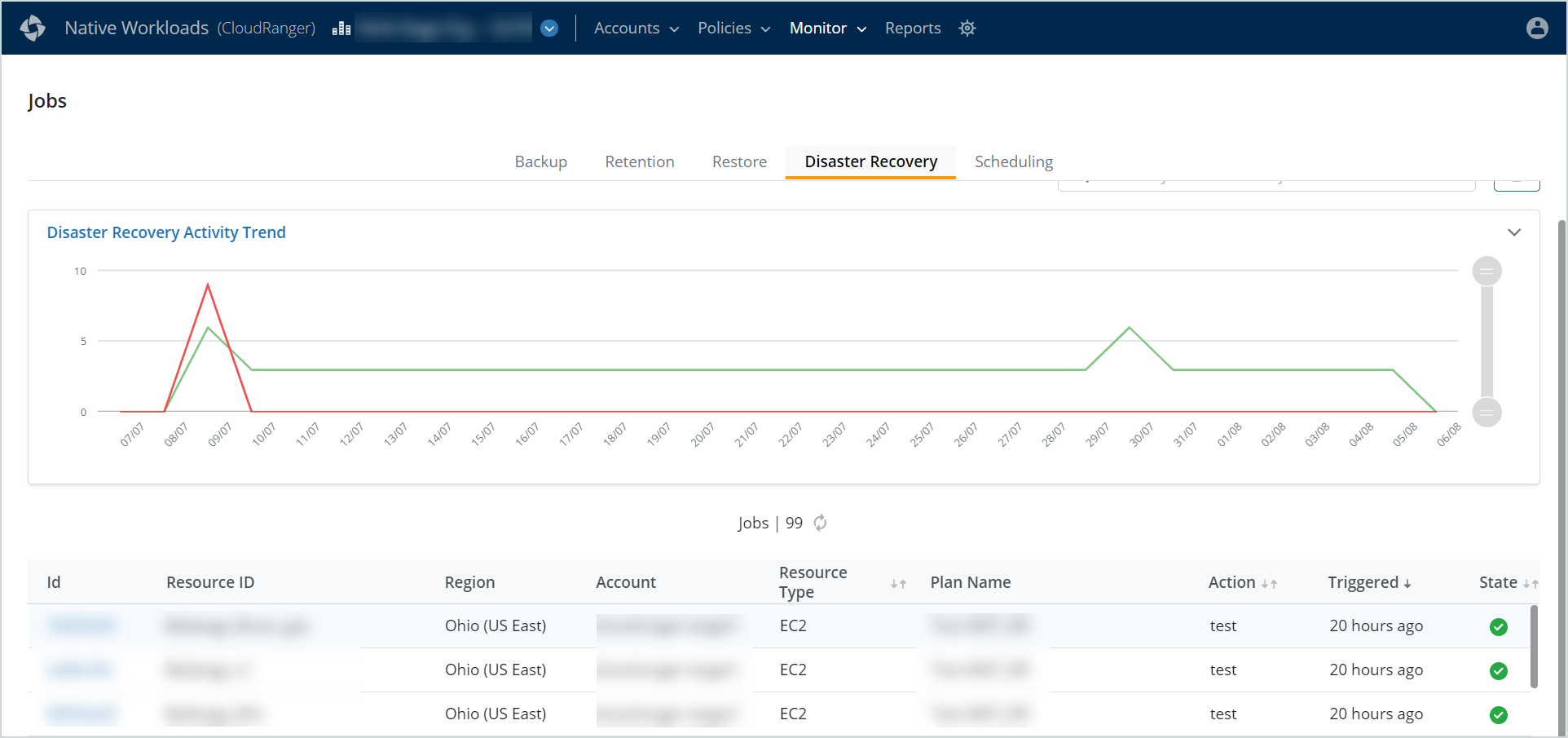
The Disaster Recovery Activity Trend chart provides a graphical view of all DR jobs in the last 30 days. Hover over the graph to view the total number of successful or failed jobs on a particular day.
The disaster recovery jobs table displays the following information for each job:
- ID: A unique identification number associated with the job.
- Resource ID: The Resource associated with the disaster recovery job.
- Region: The AWS region in which the disaster recovery job is triggered.
- Account: The CloudRanger Account on which the job is triggered.
- Resource Type: The resource type on which the job is initiated, for example, DynamoDB, EC2, RDS, or Redshift.
- Plan Name: The DR Plan that triggered the job.
- Action: The type of action initiated by the job, for example, clone.
- Triggered: The time when the job was initiated.
- State: The current status of each job.
| Success | |
| Failed | |
Note: A
Click a Disaster Recovery Job ID to view the job details.
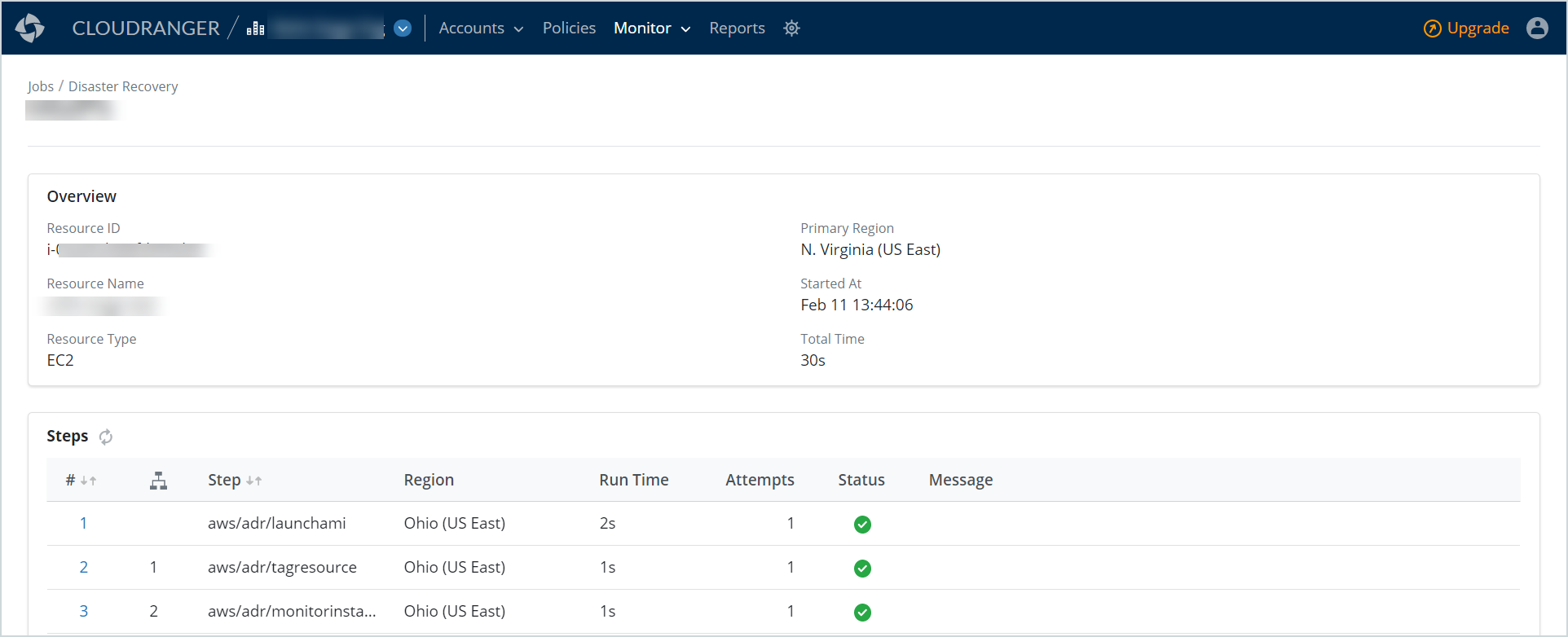
The disaster recovery job details page includes detailed information about the selected job, the job progress, and associated logs.
|
Field |
Description |
| Overview |
This section displays the following information associated with the disaster recovery:
|
|
Steps |
This section displays the stages in which the job is performed.
Note: The job steps allow you to assess each stage of the job, and the associated Messages, Run Time, and number of Attempts, in case of a failed job status. Use the Refresh icon to repeat a particular step on a failed job. |
Scheduling Jobs
The main Scheduling Jobs page lists all scheduling-related jobs that were triggered within the previous 30 days.
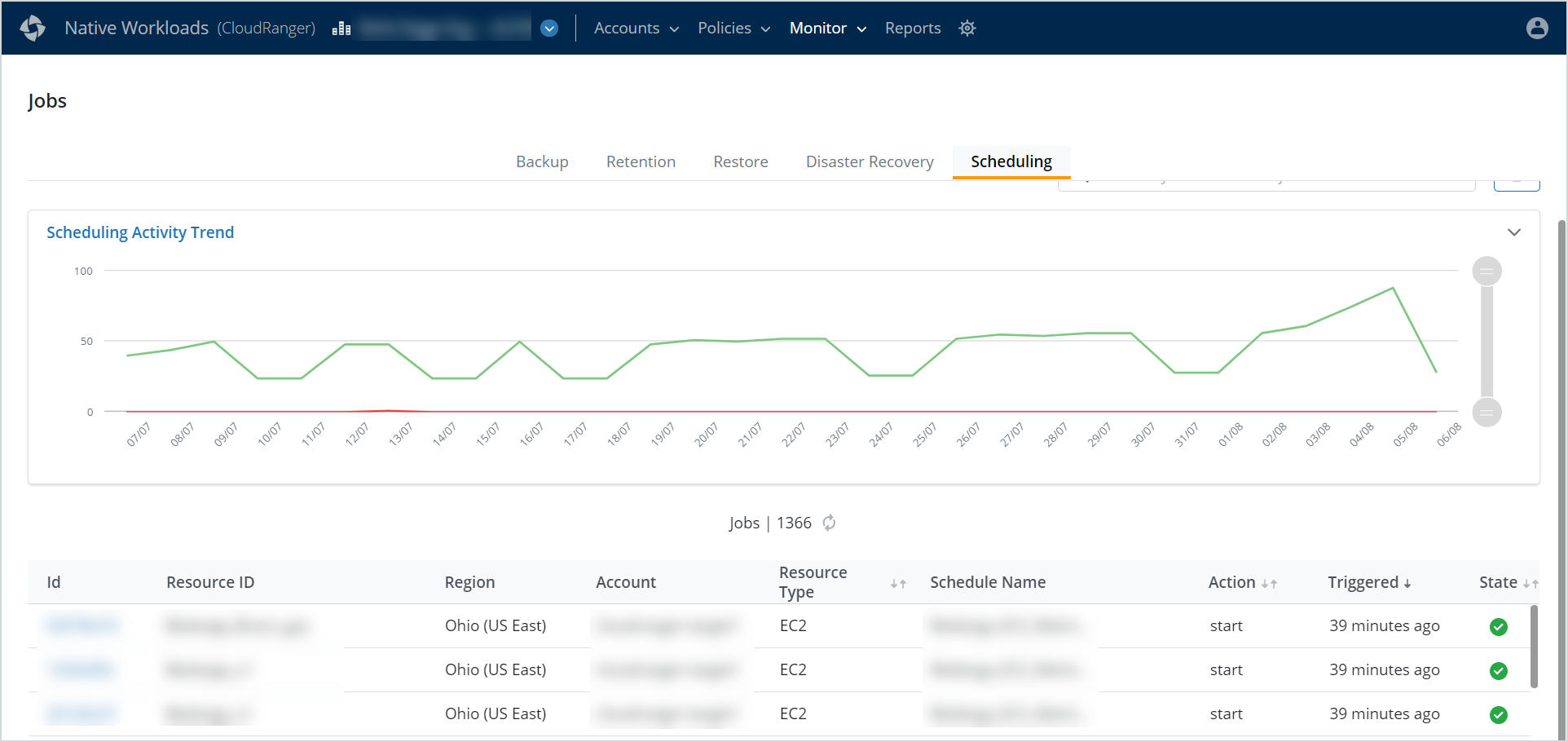
The Scheduling Activity Trend chart provides a graphical view of all scheduling jobs in the last 30 days. Hover over the graph to view the total number of successful or failed jobs on a particular day.
The scheduling jobs table displays the following information for each job:
- ID: A unique identification number associated with the job.
- Resource ID: The Resource associated with the scheduling job.
- Region: The AWS region in which the scheduling job is triggered.
- Account: The CloudRanger Account on which the job is triggered.
- Resource Type: The resource type on which the job is initiated, for example, EC2, RDS, or Redshift.
- Schedule Name: The resource schedule associated with the job.
- Action: The type of action initiated by the job, for example, start or stop.
- Triggered: The time when the job was initiated.
- State: The current status of each job.
| Success | |
| Failed | |
Note: A
Click a Scheduling Job ID to view the job details.
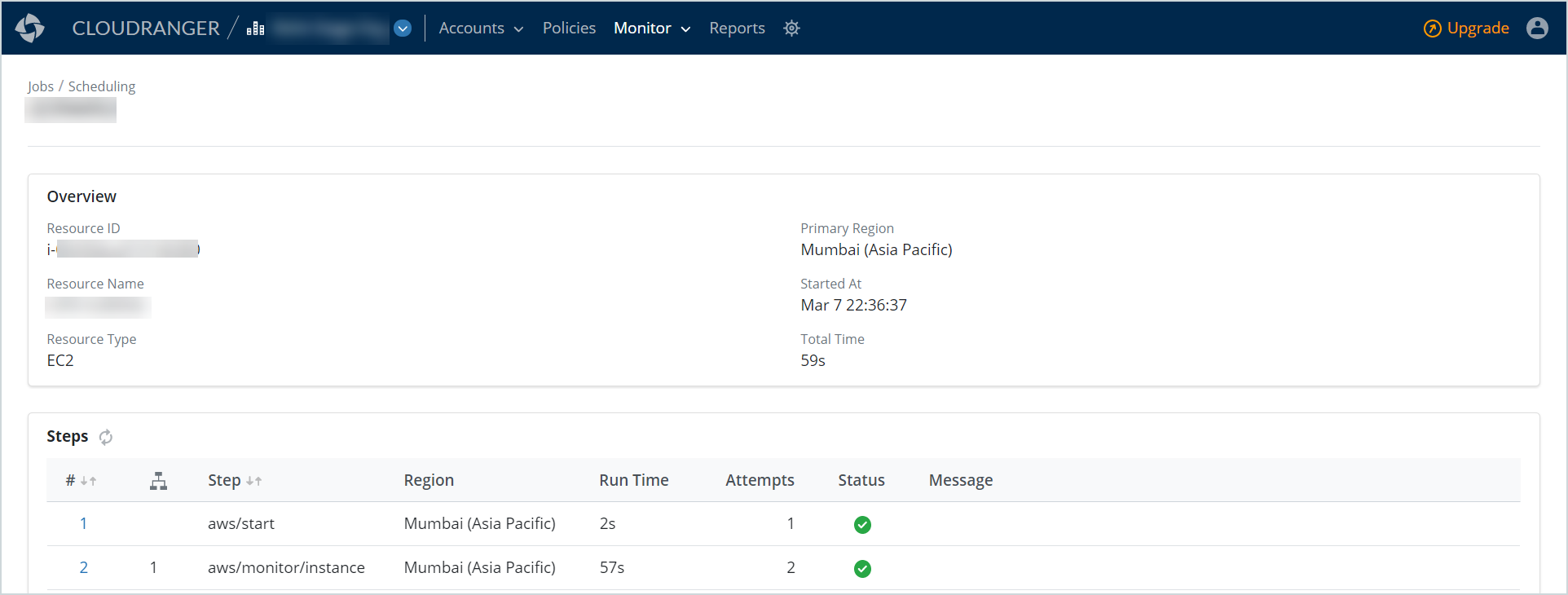
The scheduling job details page includes detailed information about the selected job, the job progress, and associated logs.
|
Field |
Description |
| Overview |
This section displays the following information associated with the scheduling:
|
|
Steps |
This section displays the stages in which the job is performed.
Note: The job steps allow you to assess each stage of the job, and the associated Messages, Run Time, and number of Attempts, in case of a failed job status. Use the Refresh icon to repeat a particular step on a failed job. |